
یادگیری ماشین یا Machine Learning مهمترین بخش از دنیای هوش مصنوعی امروز است. در بسیاری از مواقع ماشین لرنینگ و هوش مصنوعی در کنار هم و حتی گاهی بسیاری از افراد این دو واژه را بجای هم به کار میبرند.
یادگیری ماشین یکی از زیر شاخههای فناوری هوش مصنوعی است که بر توسعه الگوریتمها و مدلهای آماری تمرکز دارد که رایانهها را قادر میسازد تا وظایفی را بدون دستورالعملهای صریح انجام دهند.
در این مقاله به صورت جامع مفهوم یادگیری ماشین را بررسی میکنیم. ابتدا مفهوم و تعاریف یادگیری ماشین را مرور میکنیم، سپس انواع دستههای یادگیری ماشین را بررسی میکنیم و سپس کاربردهای یادگیری ماشین را معرفی خواهیم کرد. ما در این مقاله سعی میکنیم موضوعات را به زبان ساده توضیح دهیم.
یادگیری ماشین چیست؟
یادگیری ماشین و هوش مصنوعی
در بسیاری از منابع، عبارتهای هوش مصنوعی و یادگیری ماشین اغلب در کنار یکدیگر استفاده میشوند. حتی شاید ترکیبهایی مانند AI&ML را بسیار دیده باشید. همین موضوع باعث شده که برخی افراد این دو را معادل هم بدانند، در حالی که این تصور درست نیست.
هوش مصنوعی یک حوزه گسترده است که شامل مجموعهای از تکنیکها و رویکردها میشود. این تکنیکها شامل روشهای مختلفی مانند هوش مصنوعی نمادین، سیستمهای خبره، منطق فازی و یادگیری ماشین است. یادگیری ماشین درواقع یکی از زیرشاخههای هوش مصنوعی است که بر پایه یادگیری از دادهها برای انجام وظایف طراحی شده است.

همانطور که در تصویر بالا دیده میشود، یادگیری ماشین امروزه بخش اصلی و کاربردی هوش مصنوعی به شمار میآید. بسیاری از ابزارها و فناوریهایی که به نام هوش مصنوعی شناخته میشوند، در واقع از یادگیری ماشین، بهویژه یادگیری عمیق، استفاده میکنند. در سالهای اخیر، سایر روشهای هوش مصنوعی کمتر مورد استفاده قرار میگیرند و بیشتر در حوزههای خاص کاربرد دارند.
یادگیری ماشین چگونه کار میکند؟
یادگیری ماشین روشی است که در آن کامپیوترها به جای دستورالعملهای صریح، از دادهها یاد میگیرند. این یادگیری از طریق تحلیل دادهها و شناسایی الگوها انجام میشود. به این ترتیب، مدلهای یادگیری ماشین میتوانند مسائل مختلف را حل کنند یا نتایج را پیشبینی کنند. در ادامه مراحل کار یادگیری ماشین را به صورت گام به گام بررسی میکنیم.

مرحله اول: جمعآوری دادهها
گام اول تهیه دادههای مناسب برای آموزش مدل است. دادهها میتوانند از منابع مختلف مانند فایلها، پایگاههایداده یا اینترنت جمعآوری شوند. برای مثال، اگر هدف پیشبینی قیمت خانههاست، دادههایی مثل متراژ خانه، محله، تعداد اتاقها و قیمتهای قبلی مورد نیاز است. مثلا شما میتوانید از دادههای موجود در سایت دیوار یا شیپور استفاده کنید.
مرحله دوم: پیشپردازش دادهها
دادههای جمع آوری شده همیشه بدرد بخور نیستند و بین آنها ممکن است دادههای اضافی و اشتباه، دادههای گمشده و … وجود داشته باشد. مثلا ممکن است یکی قیمت یک خانه به اشتباه هزار تومان ثبت شده باشد یا یک خانه اصلا قیمتی برای آن ثبت نشده باشد.
در این شرایط شما باید این دادهها را جدا کنید تا به دادههای با کیفیت و پالایش شده برسید. هرچقدر دادههای شما تمیزتر و با کیفیتتر باشد، خطای مدل کمتر میشود.
مرحله سوم: انتخاب مدل و الگوریتم
حالا باید به این فکر کنید که برای حل مسئلهای که به دنبال آن هستید، چه مدل و الگوریتمی مناسب است. به عنوان مثال، شما ممکن است احساس کنید یکم رابطه خطی کفایت میکند. یا نیاز است رابطهها و الگوریتمهای دیگر به کار گرفته شود. انتخاب الگوریتم درست بسیار اهمیت دارد.
مرحله چهارم: آموزش مدل ماشین لرنینگ
حالا که دادههای مناسبی دارید و مدل و الگوریتم مناسب را نیز انتخاب کردهاید، حالا باید مدل خود را با دادهها آموزش دهید. مدل یا الگوریتم به خودی خود یک فرمول یا روش است و میتواند در هر جایی به هر شکلی استفاده شود. در این مرحله شما دادههای خود را به این مدل میدهید، تا این الگوریتم را مطابق با مسئله خودتان شخصی سازی کنید.
در واقع مدل بر اساس دادهها یاد میگیرد که چگونه مسئله شما را حل کند.
مرحله پنجم: ارزیابی مدل
مدل شما حالا میتواند کار کند اما آیا کاملا به او اعتماد دارید؟ از همین رو باید مدل را ارزیابی کنید. ارزیابی مدل به معنای این است که شما بخشی از دادههای واقعی را ( که در فرایند آموزش مدل به او نداده بودید) را به مدل میدهید و از او میخواهید خروجی را حدس بزند، اگر درست حدس زد شما میفهمید که مدل به خوبی آموزش داده شده است.
مرحله ششم: بهینهسازی مدل
در صورتی که در مرحله قبل مدل عملکرد خوبی نشان ندهد، باید مدل را بهینه کنید. در این مرحله شما یا دادههای بیشتری برای آموزش فراهم میکنید، یا ویژگیهایی را اصلاح میکنید و حتی ممکن است الگوریتمی که انتخاب کردهاید را تغییر دهید. شما اینقدر این کار را انجام میدهید و ارزیابی میکنید تا مدل عملکرد مناسب را نشان دهد.
مدل آماده است، از آن استفاده کنید.
در نهایت پس از چرخههای متعدد ارزیابی و بهینهسازی، هنگامی که مدل عملکرد مناسبی نشان داد، میتوانید آن را در دنیای واقعی استفاده کنید. مثلا حالا مدل شما میتواند قیمت خانههای جدید را تخمین بزند، یا وضعیت آب و هوا را پیشبینی کند و … . به شما تبریک میگوییم.
انواع روشهای یادگیری ماشین
یادگیری ماشین روشهای مختلفی دارد. تا به اینجای مقاله ما همه روشهای یادگیری ماشین را به یک چشم نگاه کردیم اما حالا وقت آن رسیده که انواع روشهای یادگیری ماشین را معرفی کنیم.
همانطور که میدانیم، در دنیای ماشین لرنینگ، با استفاده از مجموعهای از دادهها، مدلهای مختلف را آموزش میدهیم. طبیعی است که همیشه نوع دادهها و یا روشی که به ماشین آموزش میدهیم یکسان نباشد، از همین رو یادگیری ماشین نیز به انواع مختلفی تقسیم میشود. در ادامه سه دسته اصلی ماشین لرنینگ را به صورت کامل معرفی میکنیم.
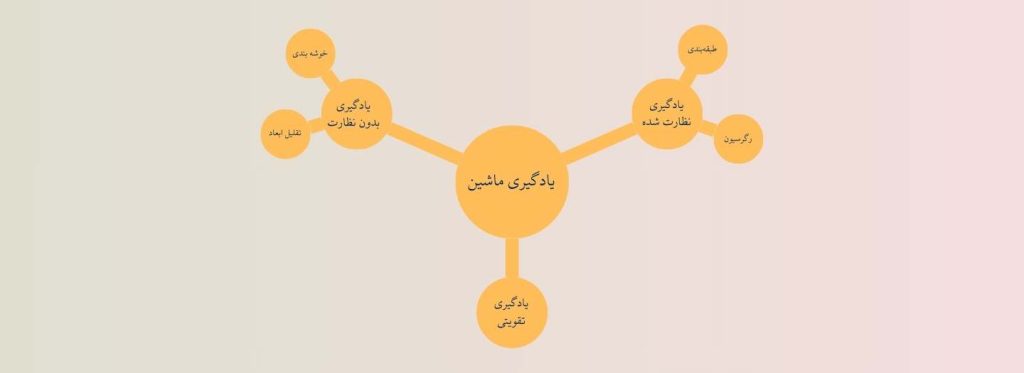
یادگیری نظارت شده یا Supervised learning
یادگیری نظارت شده حالتی از ماشین لرنینگ است که از دادههای برچسب دار برای آموزش مدل استفاده میشود. داده برچسب دار دادهای است که هم خروجی دارد و هم خروجی. مثلا متراژ خانه به عنوان داده ورودی و قیمت خانه به عنوان داده خروجی.
برای درک بهتر، دنیای یادگیری نظارت شده شبیه مشاورین املاک است، آنها خانههای زیادی را بازدید رفتهاند و قیمتها را پرسیدهاند، حالا هر خانه جدیدی که بروند، بر اساس قیمت خانههایی که قبلا دیدهاند، برای خانههای جدید یک قیمت تعیین کنند.
یادگیری نظارت شده خودش به دو بخش اصلی تقسیم میشود. طبقهبندی (Classification) و رگرسیون (Regression) دو نوع یادگیری نظارت شده هستند. یکی از مثالهای کاربردی یادگیری نظارت شده، تشخیص ایمیلهای هرزنامه یا اسپم است. هوش مصنوعی بسیاری از ایمیلهای اسپم را دیده است و حالا میتواند ایمیل جدید را بررسی کند که اسپم است یا خیر. در واقع میتوان گفت در دنیای هوش مصنوعی اکثر مواقعی که در مورد دادههای برچسب دار صحبت میکنیم، روش یادگیری نظارت شده استفاده میشود.

یادگیری بدون نظارت
یادگیری نظارت نشده یا بدون نظارت دستهای از یادگیری ماشینی است که در آن خبری از برچسبهای آموزشی نیست. هدف این است که ماشین خودش الگوها یا ساختارهای پنهان را در دادهها پیدا کند.
یادگیری بدون نظارت مثل زمانی است که بدون داشتن نقشه، وارد یک شهر جدید شدهاید. در این حالت شما مجبورید خودتان اینقدر شهر را بچرخید تا کم کم با شهر آشنا شوید. در یادگیری بدون نظارت، این خود شما هستید که الگو یا ساختار شهر را کشف میکنید و خبری از نقشه نیست.
یادگیری بدون نظارت خودش به بخشهای دیگری تقسیم میشود، تقلیل ابعاد و خوشهبندی از جمله مهمترین دستههای یادگیری بدون نظارت هستند. این روش کاربردهای بسیاری دارد، تشخیص تقلب و کلاهبرداری در موسسات مالی، تقسیم بندی مشتریان و دستهبندی اسناد بخشی از این کاربردهاست. برای آشنایی کامل با یادگیری بدون نظارت اینجا کلیک کنید.
یادگیری تقویتی یا Reinforcement learning
حالا تصور کنید دادههای چندانی در دست نیست. در این حالت دیگر نمیتوان مدل را آموزش داد، بلکه مدل یا ماشین، باید خودش تجربه کند و از تجربیات خودش بیاموزد. به این روش، یادگیری تقویتی میگوییم.
در یادگیری تقویتی، ماشین (که ما به آن عامل میگوییم)، با محیط در تعامل است. عامل اقداماتی را انجام میدهد و بر اساس آن بازخورد دریافت میکند. بازخوردها شامل پاداشها و جریمهها میباشد(مشابه با زمانی که یک کودک با با آبنات پاداش میدهیم یا تنبیه میکنیم). در این شرایط هدف عامل این است که اقدام بعدی به گونهای انجام دهد که پاداش بیشتری دریافت کند.
در حالی که روشهای یادگیری نظارت شده و بدون نظارت به دادهها تکیه دارند، یادگیری تقویتی به آزمون و خطا متکی است و خودش از نتایج خودش یاد میگیرد.

امروزه یادگیری تقویتی کاربردهای بسیار زیادی دارد. در واقع بسیاری از کاربردهای پیشرفته ماشین لرنینگ در دسته یادگیری تقویتی قرار دارند. بسیاری از بازیهای رایانهای نظیر شطرنج، Go و بازیهای ویدیویی مانند StarCraft و Dota 2 که میتوانند همانند یک انسان مقابل ما بازی کنند از این روش استفاده میکنند. رباتها و خودروهای خودران نیز همگی بر اساس این روش توسعه یافتهاند. برای آشنایی بیشتر با یادگیری تقویتی اینجا کلیک کنید.
سایر روشهای یادگیری ماشین
موارد بالا دستههای اصلی یادگیری ماشین هستند اما روشهای دیگری نیز وجود دارد. برخی از این روشها عبارتند از:
- یادگیری نیمهنظارتشده (Semi-Supervised Learning): ترکیبی از دادههای برچسبدار و بدون برچسب برای آموزش مدل.
- یادگیری چندوظیفهای (Multi-Task Learning): مدل بهطور همزمان چندین وظیفه مرتبط را یاد میگیرد.
- یادگیری انتقالی (Transfer Learning): استفاده از یک مدل آموزشدیده در یک مسئله برای حل مسئلهای دیگر.
یادگیری عمیق چیست؟
یادگیری عمیق بخشی از یادگیری ماشین یا ماشین لرنینگ است که از شبکههای عصبی با لایههای متعدد ( به همین دلیل به آن عمیق میگویند.) استفاده میکند. شبکههای عصبی برای تقلید از ساختار و عملکرد مغز انسان طراحی شدهاند و به آنها اجازه میدهند الگوهای پیچیده در دادهها را مدلسازی کنند.
یادگیری عمیق مدلهای پیچیدهتری را نسبت با یادگیری ماشین استفاده میکند. در ماشین لرنینگ الگوریتمهایی نظیر رگرسیون خطی، درخت تصمیم، ماشینهای بردار پشتیبان که نسبتاً ساده و قابل تفسیر هستند استفاده میشود. این در حالی است که در یادگیری عمیق مدلهایی مانند شبکههای عصبی کانولوشن، شبکههای عصبی مکرر، ترانسفورماتورها و … استفاده میشود.
کاربردهای یادگیری ماشین
یادگیری ماشین به عنوان اصلیترین بخش دنیای هوش مصنوعی، امروزه کاربردهای بسیاری دارد. امروزه در همه جا میتوان ردی از فناوری یادگیری ماشین پیدا کرد. در ادامه برخی از کاربردهای شاخص ماشین لرنینگ را بررسی میکینم.
پیشبینی و تحلیل مالی
یادگیری ماشین با استفاده از الگوریتمهای نظارتشده، قادر به پیشبینی روندهای مالی، قیمت سهام و شاخصهای اقتصادی است. ماشینهای بردار پشتیبان و شبکههای عصبی عمیق در این کاربرد به تحلیل دادههای مالی و شناسایی الگوهای پنهان کمک میکنند.
تشخیص پزشکی و درمانی
این کاربرد شامل تحلیل تصاویر پزشکی و دادههای بیماران است. الگوریتمهای یادگیری عمیق و نظارتشده میتوانند بیماریهایی مانند سرطان، دیابت و بیماریهای قلبی را شناسایی کنند. بهویژه شبکههای عصبی عمیق در پردازش تصاویر پزشکی بسیار موثر هستند.
پیشبینی رفتار کاربر و شخصیسازی با ماشین لرنینگ
ماشین لرنینگ در خدمات دیجیتال مانند موتورهای جستجو و توصیهگرهای محصول استفاده میشود. الگوریتمهای یادگیری نظارتشده و بدون نظارت، رفتار کاربران را شناسایی میکنند و محتواهایی را به صورت شخصیسازی شده ارائه میدهند.
حملونقل خودران
یادگیری ماشین در توسعه سیستمهای حملونقل خودکار مانند خودروهای بدون راننده نقش مهمی دارد. الگوریتمهای یادگیری تقویتی به این سیستمها کمک میکنند تا تصمیمات خود را بر اساس دادههای دریافتی از محیط اطراف بگیرند و بهینهترین مسیر را انتخاب کنند.
تشخیص تقلب در تراکنشهای مالی
با استفاده از الگوریتمهای یادگیری نظارتشده، میتوان رفتارهای مشکوک را در تراکنشهای مالی شناسایی کرد. این روشها برای حفاظت از اطلاعات مالی و جلوگیری از سوءاستفادهها بسیار مؤثر هستند.
یادگیری ماشین در تبلیغات آنلاین
در این زمینه، ماشین لرنینگ به شناسایی و تحلیل رفتار کاربران برای ارائه تبلیغات هدفمند استفاده میشود. الگوریتمهای یادگیری بدون نظارت میتوانند رفتارهای کاربران را دستهبندی کرده و تبلیغات مرتبطتر را به آنها نشان دهند.
ماشین لرنینگکاربردهای بسیار بیشتری دارد. بدون شک یادگیری ماشین و البته یادگیری عمیق، هر روز بیش از پیش به زندگی ما نفوذ میکنند و کاربردهای بیشتری از آنها در زندگی ما مشاهده خواهد شد.
ماشین لرنینگ در یک نگاه
یادگیری ماشین به روشهایی خطاب میشود که از تجربیات گذشته میآموزد و عملکرد خود را بهتر میکند. یادگیری ماشینی یک زمینه پویا و به سرعت در حال تحول است که صنایع را متحول می کند و زندگی روزمره ما را بهبود میبخشد. این فناوری در حوزههای مختلف مثل مراقبت های بهداشتی، مالی، سرگرمی، حمل و نقل و … کاربرد دارد.
ماشین لرنینگ از انواع روشهای مختلفی نظیر یادگیری نظارت شده، یادگیری بدون نظارت و یادگیری تقویتی تشکیل میشود. امروزه روشهای یادگیری عمیق، که از شبکههای عصبی استفاده میکنند، بخش مهمی از یادگیری ماشین را تشکیل دادهاند.
یادگیری ماشین هر روز حوزههای جدیدی را به تصاحب خود در میآورد و نقش مهمی در توسعه سیستمهای هوشمند دارد.







