
یادگیری تقویتی، حوزهای جذاب از یادگیری ماشین
یادگیری تقویتی یا Reinforcement Learning یکی از شاخههای مهم و پرکاربرد در زمینهی هوش مصنوعی و یادگیری ماشین است. در مقاله «یادگیری ماشین چیست؟» بررسی کردیم که یادگیری ماشین را میتوان به روشهای یادگیری نظارت شده، یادگیری نظارت نشده و یادگیری تقویتی دسته بندی کرد.
یادگیری تقویتی با الهام از نحوهی یادگیری موجودات زنده از محیط اطرافشان، به توسعهی الگوریتمها و مدلهایی میپردازد که قادر به اتخاذ تصمیمات بهینه در مواجهه با محیطهای پویا و نامعلوم هستند. در این مقاله، به معرفی کامل و جامع یادگیری تقویتی میپردازیم و مفاهیم اساسی، الگوریتمها، کاربردها و چالشهای آن را بررسی میکنیم.
یادگیری تقویتی چیست؟
یادگیری تقویتی شاخهای از یادگیری ماشین است که در آن یک عامل (Agent) با تعامل مستقیم با محیط خود، از طریق دریافت پاداشها یا تنبیهها، سیاستی را میآموزد که به او کمک میکند تصمیمات بهینهای اتخاذ کند. برخلاف یادگیری نظارتشده که بر دادههای برچسبگذاریشده متکی است، در یادگیری تقویتی، عامل بدون دانستن پاسخهای صحیح، تنها با تجربه کردن و یادگیری از پیامدهای اعمال خود، به بهبود عملکردش میپردازد.
هدف اصلی این روش، یافتن سیاستی است که مجموع پاداشهای مورد انتظار را در طول زمان بیشینه کند. برای فهم عمیقتر این مفهوم، لازم است با مفاهیم پایهای مانند عامل، محیط، وضعیتها، اعمال، پاداش و سیاست آشنا شویم.
مفاهیم پایه در یادگیری تقویتی
برای درک عمیقتر یادگیری تقویتی، ضروری است با مفاهیم پایهای که این حوزه را تشکیل میدهند آشنا شویم. این مفاهیم به ما کمک میکنند تا ساختار و عملکرد الگوریتمهای یادگیری تقویتی را بهتر بفهمیم.
عامل (Agent)
عامل موجودیتی است که تصمیمگیری میکند و در محیط عمل میکند. این عامل میتواند یک ربات، یک برنامه کامپیوتری، یا هر سیستم دیگری باشد که میخواهد از طریق تعامل با محیط، بهترین سیاست را بیاموزد. هدف عامل، انتخاب اعمالی است که منجر به کسب پاداشهای بیشتر در درازمدت شود.
محیط (Environment)
محیط جهان یا سیستمی است که عامل در آن عمل میکند و با آن تعامل دارد. محیط وضعیت فعلی را در اختیار عامل قرار میدهد و براساس اعمال عامل، به وضعیت جدیدی منتقل میشود و پاداش مربوطه را به عامل ارائه میدهد. محیط میتواند تعیینکننده (Deterministic) یا تصادفی (Stochastic) باشد.
وضعیت (State)
وضعیت نمایانگر شرایط فعلی محیط است که عامل آن را درک میکند. این وضعیت میتواند شامل اطلاعات کامل یا جزئی از محیط باشد و به عامل کمک میکند تا تصمیم بگیرد چه عملی را انجام دهد. مجموعهی تمام وضعیتهای ممکن را فضای وضعیت مینامند.
اعمال (Actions)
اعمال اقداماتی هستند که عامل میتواند در هر وضعیت انجام دهد. مجموعهی اعمال ممکن در یک وضعیت خاص، فضای عمل نامیده میشود. انتخاب عمل مناسب در هر وضعیت، نقش کلیدی در موفقیت عامل دارد.
پاداش (Reward)
پاداش بازخوردی است که عامل پس از انجام یک عمل در یک وضعیت مشخص از محیط دریافت میکند. این پاداش میتواند مثبت (تقویتکننده)، منفی (تنبیهکننده) یا صفر باشد. هدف نهایی عامل، حداکثرسازی مجموع پاداشهای دریافتشده در طول زمان است. پاداش به عامل نشان میدهد که عملکردش چقدر خوب یا بد بوده است.
سیاست (Policy)
سیاست نقشهای است که به عامل میگوید در هر وضعیت چه عملی را باید انجام دهد. سیاست میتواند قطعی (Deterministic) باشد، یعنی در هر وضعیت همواره یک عمل خاص را انتخاب کند، یا تصادفی (Stochastic) باشد، یعنی با احتمال مشخصی اعمال مختلف را انتخاب کند. یادگیری تقویتی به دنبال یافتن سیاست بهینهای است که مجموع پاداشهای مورد انتظار را بیشینه کند.
تابع ارزش (Value Function)
تابع ارزش یا Value Function معیاری است که به هر وضعیت یا جفت وضعیت-عمل یک مقدار اختصاص میدهد که نشاندهندهی مجموع پاداشهای مورد انتظار آینده از آن وضعیت یا پس از انجام آن عمل است. این تابع به عامل کمک میکند تا ارزش بلندمدت تصمیمات خود را ارزیابی کند.
- تابع ارزش وضعیت یا V(s) : ارزش یک وضعیت را با توجه به پاداشهای مورد انتظار آینده نشان میدهد.
- تابع ارزش عمل-وضعیت یا تابع Q (( Q(s, a) )) : ارزش انجام عمل در وضعیت را با توجه به پاداشهای مورد انتظار آینده نشان میدهد.
توازن آزمون و بهرهبرداری (Exploration vs. Exploitation)
یکی از چالشهای اساسی در یادگیری تقویتی، توازن بین آزمون و بهرهبرداری است. عامل باید بین آزمون (کاوش وضعیتها و اعمال جدید برای کشف پاداشهای احتمالی بیشتر) و بهرهبرداری (استفاده از دانش فعلی برای کسب پاداشهای مطمئن) تعادل برقرار کند. تمرکز بیش از حد بر هر یک میتواند منجر به عملکرد زیر بهینه شود.
یادگیری تقویتی چگونه کار میکند؟
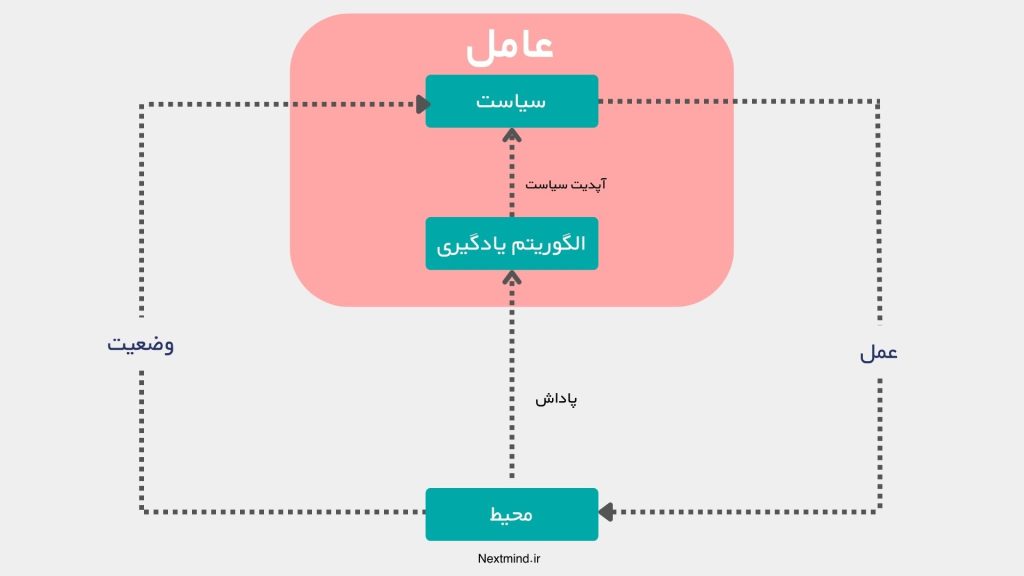
یادگیری تقویتی به صورت کلی یک فرایند یادگیری است که در آن عامل یا ایجنت با تعامل مستقیم با محیط خود، از طریق انجام اعمال (Actions) و دریافت پاداشها (Rewards)، یاد میگیرد که چگونه سیاست (Policy) خود را بهینه کند تا مجموع پاداشهای مورد انتظار را در طول زمان بیشینه سازد.
عامل در هر وضعیت (State) از محیط، تصمیم میگیرد که چه عملی را انجام دهد، سپس محیط بر اساس آن عمل به وضعیت جدیدی منتقل میشود و پاداش مربوطه را به عامل ارائه میدهد.
با تکرار این فرایند، عامل با استفاده از تابع ارزش (Value Function) به ارزیابی بلندمدت تصمیمات خود میپردازد و با توازن بین آزمون و بهرهبرداری (Exploration vs. Exploitation)، سیاست خود را بهبود میبخشد. هدف نهایی یادگیری تقویتی، یافتن سیاستی است که به عامل امکان میدهد در مواجهه با محیطهای پویا و نامعلوم، تصمیمات بهینهای اتخاذ کند که منجر به کسب پاداشهای بیشتر در درازمدت شود.
یادگیری تقویتی به زبان ساده
تصور کنید که ما یک ربات داریم که میخواهیم به او یاد بدهیم تا از یک مسیر پیچیده عبور کرده و به مقصد برسد. اما ما به جای اینکه به او نقشهی مسیر یا دستورالعملهای دقیق بدهیم، اجازه میدهیم خودش از طریق آزمون و خطا یاد بگیرد. هر بار که ربات یک حرکت انجام میدهد، اگر به مقصد نزدیکتر شود، یک پاداش (مثل امتیاز مثبت) دریافت میکند و اگر از مقصد دور شود یا به مانع برخورد کند، تنبیه (مثل امتیاز منفی) دریافت میکند.
ربات با جمعآوری این تجربیات و بازخوردها، به تدریج یاد میگیرد که کدام اقدامات او را به مقصد میرسانند و کدامها نه. این فرایند یادگیری از طریق تعامل مستقیم با محیط و دریافت پاداش یا تنبیه، یادگیری تقویتی نامیده میشود.
تفاوت یادگیری تقویتی با یادگیری نظارت شده و یادگیری نظارت نشده
در یادگیری نظارتشده ما به مدل دادههای ورودی و خروجی صحیح (برچسبگذاریشده) میدهیم؛ مثل اینکه به یک دانشآموز پاسخهای درست را بدهیم تا او یاد بگیرد. در یادگیری نظارت شده مدل سعی میکند الگوی بین ورودی و خروجی را پیدا کند تا بتواند در آینده برای ورودیهای جدید، خروجیهای درست را پیشبینی کند.
در یادگیری بدون نظارت مدل تنها دادههای ورودی را بدون هیچ برچسب یا خروجی صحیح دریافت میکند و تلاش میکند تا الگوها یا ساختارهای پنهان در دادهها را کشف کند. بنابراین، تفاوت اصلی یادگیری تقویتی با آنها در این است که مدل یا عامل در یادگیری تقویتی از طریق تعامل و تجربه با محیط و بر اساس سیستم پاداش و تنبیه، سیاست بهینه را برای تصمیمگیری یاد میگیرد، نه از طریق دادههای برچسبگذاریشده یا کشف الگوهای پنهان.
انواع روشهای یادگیری تقویتی
در یادگیری تقویتی، روشها و الگوریتمهای مختلفی توسعه یافتهاند که هر کدام به گونهای به عامل کمک میکنند تا سیاست بهینه را بیاموزد. این روشها بر اساس نحوهی تعامل با محیط و استفاده از مدل محیط، به دستههای مختلفی تقسیم میشوند. در ادامه، به معرفی و توضیح هر یک از این دستهها میپردازیم.
1. روشهای مدلمحور (Model-Based Methods)
در روشهای مدلمحور، عامل ابتدا سعی میکند مدلی از محیط را یاد بگیرد یا از مدل موجود محیط استفاده کند. این مدل شامل اطلاعاتی دربارهی انتقال وضعیتها (Transition Dynamics) و پاداشها است. با داشتن این مدل، عامل میتواند با استفاده از تکنیکهای برنامهریزی مانند برنامهنویسی دینامیک (Dynamic Programming) سیاست بهینه را محاسبه کند.
برنامهنویسی دینامیک (Dynamic Programming)
برنامه نویسی داینامیک بر اساس اصل بهینگی بلمن (Bellman Optimality Principle) عمل میکند و با استفاده از معادلات بازگشتی، تابع ارزش را محاسبه میکند. نیازمند دانستن مدل کامل محیط است و در مسائل با فضای حالت کوچک و تعیینکننده مؤثر است.
2. روشهای بدون مدل (Model-Free Methods)
در این روشها، عامل بدون داشتن مدل محیط و تنها از طریق تعامل مستقیم با محیط و مشاهدهی پاداشها، سیاست بهینه را یاد میگیرد. این روشها به دو دستهی اصلی تقسیم میشوند که در ادامه آنها را معرفی خواهیم کرد.
روشهای مبتنی بر ارزش (Value-Based Methods )
روشهای مبتنی بر ارزش به عامل کمک میکنند تا یاد بگیرد که بودن در یک وضعیت خاص یا انجام یک عمل مشخص، چقدر خوب یا مفید است.
تصور کنید که عامل میخواهد به مقصدی برسد و برای این کار باید در هر لحظه تصمیم بگیرد کدام مسیر را انتخاب کند. در این روشها، عامل به هر وضعیت یا عمل یک “امتیاز” یا “ارزش” اختصاص میدهد که نشاندهندهی میزان پاداش مورد انتظار در آینده است. سپس با مقایسهی این ارزشها، عمل یا مسیری را انتخاب میکند که بالاترین ارزش را دارد. به عبارت ساده، عامل یاد میگیرد که اگر اکنون یک عمل خاص را انجام دهد، در درازمدت چقدر پاداش دریافت خواهد کرد و بر اساس این پیشبینی، تصمیمات خود را بهینه میکند.
- الگوریتمهای مونتکارلو (Monte Carlo Methods)
الگوریتمهای مونتکارلو در یادگیری تقویتی به عامل اجازه میدهند با اجرای چندین بار یک مسیر کامل (Episode) در محیط، پاداشهای کسبشده را ثبت کند. سپس با محاسبهی میانگین این پاداشها برای هر وضعیت یا عمل، ارزش آنها را تخمین میزند. به زبان ساده، عامل با تجربه کردن کل مسیرها و دیدن نتایج نهایی، یاد میگیرد کدام تصمیمات در درازمدت پاداشهای بیشتری به همراه دارند.
- روشهای تفاوت زمانی (Temporal Difference Learning)
روشهای تفاوت زمانی به عامل کمک میکنند تا ارزش وضعیتها را به صورت تدریجی و با هر گام بهروزرسانی کند، بدون این که نیاز باشد تا پایان مسیر صبر کند. در این روش، عامل پس از انجام یک عمل و دریافت پاداش، ارزش پیشبینیشده برای وضعیت قبلی را با استفاده از پاداش فعلی و ارزش پیشبینیشده برای وضعیت جدید اصلاح میکند. این کار با محاسبه اختلاف بین پیشبینی فعلی و واقعیت انجام میشود که به آن خطای تفاوت زمانی میگویند. به زبان ساده، عامل با هر تجربه کوچک، پیشبینیهای خود را بهبود میبخشد و یاد میگیرد که در آینده تصمیمات بهتری بگیرد. در ادامه به صورت مختصر برخی از این روشها را بررسی میکنیم.
1. الگوریتم TD(0)
TD(0) به عامل اجازه میدهد پس از هر گام، ارزش وضعیت فعلی را با استفاده از پاداش دریافتی و ارزش وضعیت بعدی کمی بهروزرسانی کند. به زبان ساده، عامل بعد از هر عمل، دیدگاهش را دربارهی وضعیت فعلی اصلاح میکند بر اساس آنچه بلافاصله بعد از آن رخ داده است.
2. الگوریتم TD(λ)
TD(λ) به عامل کمک میکند علاوه بر گام بعدی، تأثیر چندین گام آینده را نیز در یادگیری لحاظ کند، با تنظیم پارامتری به نام λ (لامبدا). به زبان ساده، عامل با نگاه به چند قدم جلوتر، تصمیماتش را بر اساس ترکیبی از تجربیات کوتاهمدت و بلندمدت بهبود میبخشد.
3. الگوریتم SARSA
SARSA به عامل یاد میدهد که با پیروی از سیاست فعلیاش، ارزش هر جفت وضعیت-عمل را یاد بگیرد. به زبان ساده، عامل میآموزد در هر وضعیت چه عملی را بر اساس تصمیمات فعلیاش انجام دهد تا به بهترین نتایج برسد.
4. الگوریتم Q-Learning
Q-Learning به عامل امکان میدهد بهترین عمل ممکن را در هر وضعیت یاد بگیرد، آن هم بدون توجه به سیاست فعلی . به زبان ساده، عامل ارزش هر عمل را بر اساس بیشترین پاداش ممکن در آینده بهروزرسانی میکند تا به بهترین تصمیمها برسد.
5. الگوریتم Expected SARSA
Expected SARSA شبیه SARSA است، اما به جای تکیه بر عمل بعدی، از میانگین ارزش تمامی اعمال ممکن در وضعیت بعدی استفاده میکند. به زبان ساده، عامل با در نظر گرفتن همهی اقدامات ممکن، ارزشها را پایدارتر و دقیقتر بهروزرسانی میکند.
6. الگوریتمهای ( n )-مرحلهای
در این الگوریتمها، عامل از پاداشهای چند گام آینده (مثلاً گام) برای بهروزرسانی ارزشها استفاده میکند. به زبان ساده، عامل تأثیر تصمیماتش را تا چند قدم جلوتر میسنجد و ارزشهایش را بر اساس نتایج گامهای بعدی تنظیم میکند.
روشهای مبتنی بر سیاست (Policy-Based Methods )
روشهای ترکیبی (Actor-Critic Methods )
3. یادگیری تقویتی عمیق (Deep Reinforcement Learning )
یادگیری تقویتی عمیق ترکیبی از یادگیری تقویتی و یادگیری عمیق است که به عامل اجازه میدهد در محیطهای پیچیده و با دادههای بزرگ یاد بگیرد و تصمیم بگیرد.
در یادگیری تقویتی سنتی، عامل ممکن است برای پردازش و ذخیره تمام وضعیتها و اعمال ممکن دچار مشکل شود، به ویژه در محیطهایی با فضای حالت بزرگ. با استفاده از شبکههای عصبی عمیق ، عامل میتواند الگوها و ویژگیهای مهم را از دادهها استخراج کرده و توابع ارزش یا سیاستها را به صورت مؤثر تقریب بزند.
سادهتر میتوان گفت، یادگیری تقویتی عمیق مانند آن است که به عامل یک مغز قدرتمند بدهیم تا بتواند در موقعیتهای پیچیده و با اطلاعات فراوان، بهتر یاد بگیرد و تصمیم بگیرد . این رویکرد امکان میدهد تا عاملها وظایف چالشبرانگیزی مانند بازیهای ویدئویی در سطح انسانی، کنترل رباتهای پیچیده یا حتی رانندگی خودکار را انجام دهند.
کاربردهای یادگیری تقویتی
یادگیری تقویتی به عنوان یکی از شاخههای مهم هوش مصنوعی، در حل مسائل پیچیده و پویا که نیاز به تصمیمگیریهای متوالی دارند، نقش کلیدی ایفا میکند. این روش با امکان یادگیری از طریق تعامل مستقیم با محیط، در کاربردهای متنوعی در دنیای واقعی به کار گرفته شده است. در ادامه برخی از کاربردهای یادگیری تقویتی را بررسی میکنیم.
بازیها
یادگیری تقویتی در توسعه عاملهایی که میتوانند بازیهای پیچیده را با سطحی برابر یا بالاتر از انسانها انجام دهند، نقش مهمی دارد. به عنوان مثال، الگوریتم AlphaGo با استفاده از یادگیری تقویتی توانست قهرمان جهان در بازی Go را شکست دهد. در اینجا، یادگیری تقویتی به عامل اجازه میدهد استراتژیهای بهینه را از طریق تجربه و آزمون و خطا بیاموزد.
رباتیک
در رباتیک، یادگیری تقویتی برای آموزش رباتها به منظور انجام وظایف پیچیده مانند راه رفتن، تعادل، گرفتن اشیاء و تعامل با محیطهای ناشناخته استفاده میشود. یادگیری تقویتی به رباتها امکان میدهد بدون برنامهریزی دقیق از پیش، رفتارهای مؤثر را از طریق تجربه یاد بگیرند و با محیطهای دینامیک سازگار شوند.
خودروهای خودران
یادگیری تقویتی در توسعه سیستمهای رانندگی خودکار برای خودروها نقش اساسی دارد. با استفاده از این روش، خودروها میتوانند تصمیمگیریهای پیچیدهای مانند تغییر لاین، رعایت قوانین ترافیکی و واکنش به موقعیتهای غیرمنتظره را از طریق یادگیری از تجربیات خود انجام دهند. یادگیری تقویتی به خودروهای خودران کمک میکند تا با محیطهای پویا و عدم قطعیتها سازگار شوند.
سیستمهای توصیهگر
در پلتفرمهای آنلاین مانند فروشگاههای اینترنتی و شبکههای اجتماعی، یادگیری تقویتی برای شخصیسازی پیشنهادها به کاربران استفاده میشود. با تحلیل تعاملات کاربران و بازخوردهای آنها، سیستم میآموزد که چه محتوایی را به هر کاربر پیشنهاد دهد تا رضایت و تعامل بیشتری ایجاد شود. یادگیری تقویتی به سیستم کمک میکند سیاستهای توصیه را برای هر کاربر بهینهسازی کند.
مدیریت منابع و بهینهسازی
در مدیریت شبکهها، تخصیص منابع در مراکز داده، و بهینهسازی مصرف انرژی، یادگیری تقویتی به کار میرود. به عنوان مثال، در شبکههای ارتباطی، میتوان از آن برای بهینهسازی تخصیص پهنای باند و کاهش تأخیر استفاده کرد. یادگیری تقویتی با تصمیمگیریهای بهینه در زمان واقعی، به افزایش کارایی و کاهش هزینهها کمک میکند.
امور مالی و تجارت الگوریتمی
در حوزه مالی، یادگیری تقویتی برای توسعه استراتژیهای ترید الگوریتمی استفاده میشود. با تحلیل دادههای بازار و یادگیری از واکنشهای گذشته، عامل میتواند تصمیمات خرید و فروش بهینه را اتخاذ کند. یادگیری تقویتی به سیستمها کمک میکند تا در محیطهای مالی پیچیده و پرتلاطم، سود را بیشینه و ریسک را کاهش دهند.
آینده یادگیری تقویتی
یادگیری تقویتی در آینده نقش بسیار مهمتری در توسعه هوش مصنوعی و فناوریهای پیشرفته ایفا خواهد کرد. با پیشرفت در الگوریتمها و افزایش قدرت محاسباتی، انتظار میرود که روشهای یادگیری تقویتی بتوانند مسائل پیچیدهتر و گستردهتری را حل کنند.
یکی از زمینههای مهم تحقیقات، ترکیب یادگیری تقویتی با یادگیری عمیق و سایر شاخههای یادگیری ماشین است تا عاملها بتوانند در محیطهای پیچیده با دادههای کمتر و کارایی بالاتر یاد بگیرند. همچنین، تمرکز بر بهبود کارایی نمونهای (Sample Efficiency)، کاهش نیاز به آزمون و خطا، و افزایش پایداری و ایمنی الگوریتمها از اولویتهای آینده خواهد بود.
کاربردهای جدیدی در حوزههایی مانند پزشکی، حملونقل، اقتصاد، انرژی و حتی تعامل انسان و ماشین بروز خواهد کرد که توسط یادگیری تقویتی ممکن میشوند. در مجموع، یادگیری تقویتی با گسترش مرزهای هوش مصنوعی، به ایجاد سیستمهای هوشمندتر، تطبیقپذیرتر و کارآمدتر کمک خواهد کرد که میتوانند در مواجهه با چالشهای پیچیده جهان واقعی تصمیمات بهینه اتخاذ کنند.
جمعبندی
یادگیری تقویتی به عنوان یکی از مهمترین و پویاترین شاخههای یادگیری ماشین، دریچهای نو به سوی توسعهی سیستمهای هوشمند باز کرده است که میتوانند از طریق تعامل مستقیم با محیط، تصمیمات بهینه اتخاذ کنند. با درک مفاهیم پایهای مانند عامل، محیط، وضعیتها، اعمال، پاداش و سیاست، و آشنایی با روشها و الگوریتمهای مختلف، میتوان به عمق این حوزه پی برد.
کاربردهای گستردهی یادگیری تقویتی در زمینههایی مانند بازیها، رباتیک، خودروهای خودران، سیستمهای توصیهگر، مدیریت منابع و امور مالی نشاندهندهی ظرفیت بالای آن در حل مسائل پیچیدهی جهان واقعی است. با توجه به پیشرفتهای سریع در این حوزه و ترکیب آن با تکنیکهای یادگیری عمیق، انتظار میرود که یادگیری تقویتی در آینده نقشی کلیدی در توسعهی فناوریهای پیشرفته و ایجاد سیستمهای هوشمندتر و سازگارتر ایفا کند.







