
در عصر دادههای بزرگ، الگوریتمهای یادگیری ماشین اغلب با مجموعهدادههایی با ابعاد بالا مواجه میشوند. دادههای با ابعاد بالا میتوانند چالشهای قابل توجهی ایجاد کنند، از جمله افزایش پیچیدگی محاسباتی، افزایش احتمال بیشبرازش و دشواری درک و تجسم دادهها. کاهش ابعاد یا تقلیل ابعاد تکنیکی حیاتی در یادگیری ماشین و تحلیل داده است که با کاهش تعداد ویژگیها، این چالشها را برطرف میکند، بدون آنکه اطلاعات مهم دادهها از بین برود.
درک کاهش ابعاد
کاهش ابعاد را میتوان با مثال یک پرسشنامه ساده توضیح داد. تصور کنید پرسشنامهای طراحی کردهاید که از افراد میخواهد به ۱۰۰ سؤال مختلف پاسخ دهند تا نگرش آنها را درباره یک موضوع بسنجید. پاسخ به این تعداد سؤال زمانبر است و ممکن است بسیاری از سؤالات اطلاعات مشابهی ارائه دهند. با استفاده از کاهش ابعاد، میتوانید سؤالات مشابه یا کماهمیت را شناسایی و حذف کنید و پرسشنامه را به تعداد کمتری سؤال کاهش دهید، مثلاً به ۱۰ سؤال کلیدی. این کار نهتنها فرآیند جمعآوری دادهها را سادهتر میکند، بلکه تحلیل نتایج را نیز آسانتر کرده و همچنان اطلاعات اصلی مورد نیاز را حفظ میکند.
اهمیت تقلیل ابعاد در هوش مصنوعی
انواع روشهای کاهش ابعاد
روشهای کاهش ابعاد به طور کلی به دو دسته تقسیم میشوند:
- انتخاب ویژگی (Feature Selection): انتخاب زیرمجموعهای از ویژگیهای اصلی که بیشترین اطلاعات را دارند.
- استخراج ویژگی (Feature Extraction): ترکیب ویژگیهای موجود برای ساختن ویژگیهای جدید و مفید.
انتخاب ویژگی
انتخاب ویژگی فرآیندی است که در آن از بین تمامی ویژگیهای موجود در یک مجموعه داده، زیرمجموعهای از ویژگیهای مهم و مرتبط انتخاب میشود. هدف این است که با حذف ویژگیهای زائد، کماهمیت یا همبسته، مدلهای یادگیری ماشین را سادهتر و کارآمدتر کنیم. این کار به بهبود دقت مدل، کاهش پیچیدگی محاسباتی و جلوگیری از بیشبرازش کمک میکند. روشهای مختلفی برای انتخاب ویژگی وجود دارد:
روشهای فیلتر (Filter Methods)
روشهای پوششی (Wrapper Methods)
روشهای پوششی (Wrapper Methods) در انتخاب ویژگی از مدلهای یادگیری ماشین برای ارزیابی ترکیبهای مختلف ویژگیها استفاده میکنند. در این روشها، زیرمجموعههای مختلفی از ویژگیها تشکیل میشود و هر زیرمجموعه به عنوان ورودی به یک مدل یادگیری ماشین داده میشود. عملکرد مدل بر روی مجموعه داده آموزشی سنجیده میشود و زیرمجموعهای که بهترین عملکرد را دارد انتخاب میشود.
این فرآیند به صورت تکراری انجام میشود و ممکن است از الگوریتمهای جستجوی مختلفی مانند پیشروی (Forward Selection) ، که در آن ویژگیها به تدریج اضافه میشوند، پسرو (Backward Elimination) ، که در آن ویژگیها به تدریج حذف میشوند، یا روشهای مبتنی بر جستجوی تصادفی استفاده شود.
مزیت اصلی روشهای پوششی این است که تأثیر ترکیب ویژگیها را بر عملکرد نهایی مدل در نظر میگیرند، که میتواند به یافتن زیرمجموعهای از ویژگیها که بهترین نتایج را ارائه میدهد کمک کند. با این حال، این روشها نیازمند محاسبات بیشتری هستند زیرا مدل باید برای هر ترکیب از ویژگیها آموزش داده شود، که در مجموعهدادههای بزرگ و با تعداد ویژگیهای زیاد ممکن است زمانبر باشد.
روشهای تعبیهشده (Embedded Methods)
روشهای تعبیهشده در انتخاب ویژگی رویکردهایی هستند که انتخاب ویژگیها را بهطور مستقیم در حین آموزش مدل یادگیری ماشین انجام میدهند. در این روشها، مدل یادگیری به گونهای طراحی میشود که همزمان با یادگیری پارامترهای مدل، ویژگیهای مهم و مرتبط را نیز شناسایی و انتخاب کند. این کار معمولاً با اضافه کردن ترمهای پنالتی یا منظمسازی به تابع هزینه مدل انجام میشود، مانند رگرسیون لاسو (Lasso Regression) که از پنالتی استفاده میکند تا ضرایب ویژگیهای کماهمیت را به صفر نزدیک کند.
مزیت اصلی روشهای تعبیهشده این است که با ترکیب انتخاب ویژگی و آموزش مدل در یک مرحله، به کاهش پیچیدگی محاسباتی و جلوگیری از بیشبرازش کمک میکنند، در نتیجه بهبود کارایی و دقت مدلهای یادگیری ماشین را امکانپذیر میسازند.
استخراج ویژگی
استخراج ویژگی فرآیندی است که در آن از ترکیب یا تبدیل ویژگیهای اصلی، ویژگیهای جدید و کمابعادتری ایجاد میشود. هدف این است که با حفظ اطلاعات مهم دادهها، آنها را به فضایی با ابعاد کمتر نگاشت کنیم تا تحلیل و پردازش دادهها کارآمدتر شود. این روش به مدلهای یادگیری ماشین کمک میکند تا با دادههای سادهشده، عملکرد بهتری داشته باشند و پیچیدگی محاسباتی کاهش یابد.
روشهای استخراج ویژگی را میتوان به دو دسته روشهای خطی و روشهای غیر خطی تقسیم بندی کرد.
روشهای خطی
روشهای خطی در کاهش ابعاد، به روشهایی اشاره دارند که از تبدیلات خطی برای نگاشت دادهها از فضای با ابعاد بالا به فضای با ابعاد کمتر استفاده میکنند. این روشها فرض میکنند که روابط بین ویژگیها خطی است و با ترکیب خطی ویژگیهای اصلی، ویژگیهای جدید و کمبعدی ایجاد میکنند. در ادامه برخی از این روشها را بررسی میکنیم.
تحلیل مؤلفههای اصلی
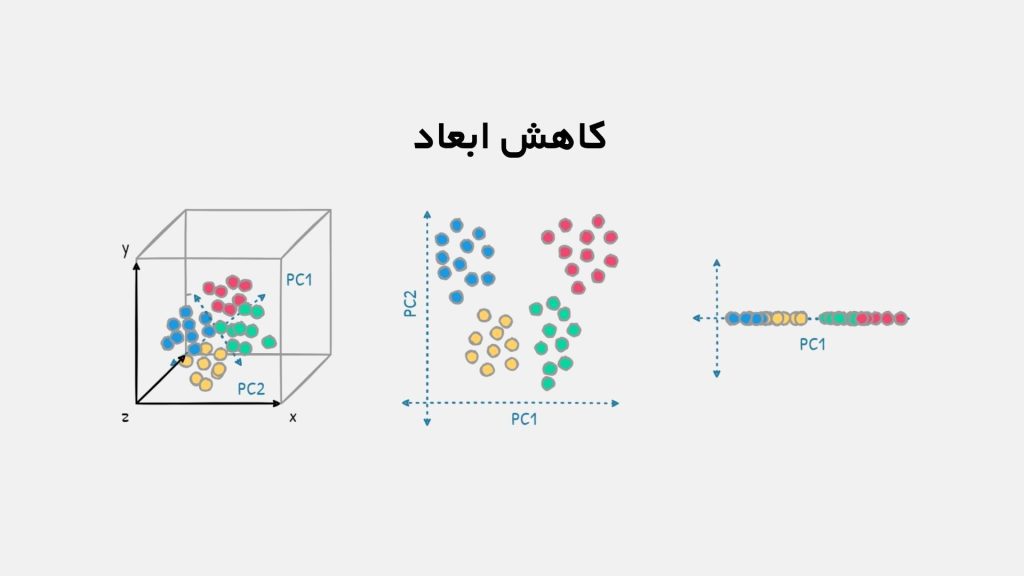
تحلیل مؤلفههای اصلی (PCA) یک روش خطی در کاهش ابعاد است که با تبدیل دادههای با ابعاد بالا به مجموعهای از مؤلفههای اصلی کمبعدتر، اما همچنان حاوی بیشترین اطلاعات ممکن، کار میکند. در PCA، مؤلفههای اصلی ترکیبات خطی از ویژگیهای اولیه هستند و به گونهای انتخاب میشوند که بیشترین واریانس دادهها را در خود داشته باشند.
اولین مؤلفه اصلی بیشترین واریانس را توضیح میدهد، دومی بیشترین واریانس باقیمانده را در راستای عمود بر مؤلفه اول، و به همین ترتیب. این فرآیند نهتنها ابعاد دادهها را کاهش میدهد، بلکه همبستگی بین ویژگیها را حذف کرده و دادهها را به فضای جدیدی منتقل میکند که در آن مؤلفهها غیرهمبسته هستند. در نتیجه این روش با حفظ ساختار اصلی و اطلاعات مهم، به سادهسازی مدلهای یادگیری ماشین، کاهش پیچیدگی محاسباتی و تسهیل در تجسم و تحلیل دادهها کمک میکند.
به عنوان مثال، در تصویربرداری دیجیتال، تصاویر با وضوح بالا دارای تعداد پیکسلهای زیادی هستند. با استفاده از تحلیل مولفه اصلی، میتوانیم تصاویر را به مؤلفههای اصلی کاهش دهیم و در نتیجه حجم دادهها را بدون از دست دادن جزئیات مهم کاهش دهیم.
تحلیل تفکیک خطی
تحلیل تفکیک خطی (LDA) یک روش خطی در کاهش ابعاد و دستهبندی نظارتشده است که هدف آن یافتن ترکیبات خطی از ویژگیهای اصلی است که بهترین جداسازی بین دو یا چند کلاس را فراهم میکند. در تحلیل تفکیک خطی، فضای ویژگیها به گونهای تغییر مییابد که فاصله بین کلاسها (میانگین کلاسها) بیشینه و پراکندگی درون کلاسی کمینه شود.
این کار با یافتن محورهای جدیدی انجام میشود که دادهها روی آنها پرتاب میشوند، به طوری که تفاوتها و ساختارهای مرتبط با برچسبهای کلاس در فضای کاهشیافته حفظ میشود. در نتیجه، تحلیل تفکیک خطی علاوه بر کاهش ابعاد، با تاکید بر ویژگیهای مهم برای تمایز کلاسها، به بهبود عملکرد مدلهای دستهبندی کمک میکند.
روشهای غیر خطی
روشهای غیرخطی در کاهش ابعاد، تکنیکهایی هستند که با حفظ روابط غیرخطی و پیچیده بین ویژگیها، دادهها را به فضای با ابعاد کمتر نگاشت میکنند. این روشها قادرند ساختارها، الگوها و منیفلدهای غیرخطی پنهان در دادهها را کشف کنند، که با روشهای خطی قابل شناسایی نیستند. در ادامه مشهورترین این روشها را بررسی میکنیم.
نقشهبرداری همسایگی حفظکننده یا Isomap
نقشهبرداری همسایگی حفظکننده (Isomap) یک روش کاهش ابعاد غیرخطی است که هدف آن حفظ ساختار هندسی و روابط غیرخطی دادههای با ابعاد بالا در فضای کاهشیافته است. Isomap ابتدا یک گراف همسایگی از دادهها ایجاد میکند، به طوری که هر نقطه به همسایگان نزدیک خود متصل میشود. سپس با استفاده از این گراف، فاصلههای ژئودزیک (کوتاهترین مسیرها بر روی منیفلد) بین تمام جفتهای نقاط محاسبه میشود. در نهایت، با بهکارگیری مقیاسبندی چندبعدی (MDS)، دادهها را به فضایی با ابعاد کمتر نگاشت میکند، بهگونهای که فاصلههای ژئودزیک بین نقاط تا حد امکان حفظ شوند. این فرآیند به Isomap امکان میدهد تا ساختارهای پیچیده و منیفلدهای نهفته در دادهها را کشف کند و برخلاف روشهای خطی مانند PCA، روابط غیرخطی بین دادهها را نیز در فضای کاهشیافته حفظ کند.
t-SNE
t-SNE (t-Distributed Stochastic Neighbor Embedding) یک روش کاهش ابعاد غیرخطی است که برای تجسم دادههای با ابعاد بالا در فضای دو یا سه بعدی به کار میرود. t-SNE با مدلسازی توزیع احتمالاتی از فاصلههای بین نقاط داده در فضای با ابعاد بالا شروع میکند، به گونهای که نقاط نزدیکتر احتمال بالاتری برای همسایگی دارند. سپس سعی میکند نگاشتی به فضای کمبعد پیدا کند که این توزیع احتمالات را تا حد امکان حفظ کند.
این روش بر حفظ روابط محلی بین دادهها تمرکز دارد، به طوری که نقاطی که در فضای اصلی به هم نزدیک هستند، در فضای کاهشیافته نیز نزدیک باقی بمانند. نتیجه t-SNE یک تجسم است که ساختارهای خوشهای و الگوهای پنهان در دادهها را بهخوبی نشان میدهد، که در تحلیل و درک دادههای پیچیده مانند تصاویر، متن و دادههای زیستی بسیار مفید است.
Autoencoders
خودرمزگذارها یا Autoencoders شبکههای عصبی مصنوعی هستند که برای یادگیری نمایش فشرده یا کدگذاری دادهها به صورت بدون نظارت استفاده میشوند. ساختار آنها شامل دو بخش اصلی است: رمزگذار (Encoder) که دادههای ورودی با ابعاد بالا را به یک نمایش فشرده با ابعاد کمتر نگاشت میکند، و رمزگشا (Decoder) که تلاش میکند این نمای فشرده را به دادههای اصلی بازسازی کند.
هدف از آموزش خودرمزگذارها، به حداقل رساندن تفاوت بین ورودی و خروجی بازسازیشده است، که منجر به یادگیری ویژگیهای مهم و الگوهای پنهان در دادهها میشود. خودرمزگذارها به عنوان یک روش استخراج ویژگی در کاهش ابعاد استفاده میشوند و قادرند روابط غیرخطی پیچیده بین ویژگیها را مدلسازی کنند، که در کاربردهایی مانند فشردهسازی تصویر ، تشخیص ناهنجاری و پیشپردازش دادهها بسیار مفید هستند.
کاربردها و مزایای کاهش ابعاد در هوش مصنوعی
کاهش ابعاد در علوم داده و هوش مصنوعی کاربردهای گستردهای دارد. یکی از مهمترین کاربردهای آن تجسم دادهها است. وقتی با مجموعهدادههایی با ویژگیهای بسیار زیاد (ابعاد بالا) روبهرو هستیم، تجسم و درک آنها دشوار میشود. با استفاده از کاهش ابعاد، میتوانیم دادهها را به دو یا سه بُعد کاهش دهیم و آنها را روی نمودارها و گرافها نمایش دهیم. این کار به ما کمک میکند تا الگوها، خوشهبندیها و روابط پنهان بین دادهها را شناسایی کنیم و درک بهتری از ساختار دادهها به دست آوریم.
کاربرد دیگر کاهش ابعاد در بهبود عملکرد الگوریتمهای یادگیری ماشین است. وقتی تعداد ویژگیها زیاد باشد، الگوریتمها ممکن است کند عمل کنند و حتی دچار بیشبرازش شوند، یعنی روی دادههای آموزشی خوب عمل کنند اما روی دادههای جدید عملکرد ضعیفی داشته باشند. با کاهش ابعاد و حذف ویژگیهای غیرضروری یا کماهمیت، مدلها سادهتر شده و سرعت پردازش افزایش مییابد. همچنین، کاهش ابعاد به کاهش نویز در دادهها کمک کرده و باعث افزایش دقت مدلها میشود. علاوه بر این، نیاز به فضای ذخیرهسازی کمتر برای دادهها و کاهش هزینههای محاسباتی از دیگر مزایای کاربردی کاهش ابعاد هستند.
چگونه روش مناسب برای کاهش ابعاد را انتخاب کنیم؟
انتخاب روش مناسب برای کاهش ابعاد به عوامل متعددی بستگی دارد، از جمله ماهیت دادهها ، اهداف تحلیل و نیازهای خاص پروژه . اگر دادههای شما دارای روابط خطی هستند و حفظ واریانس کلی دادهها مهم است، روشهای خطی مانند تحلیل مؤلفههای اصلی (PCA) مناسباند.
در صورتی که دادهها دارای ساختارهای غیرخطی پیچیده هستند، روشهای غیرخطی مانند t-SNE یا Isomap میتوانند بهتر الگوهای پنهان را آشکار کنند.
اگر تفسیرپذیری ویژگیها برای شما اهمیت دارد، انتخاب ویژگی را مدنظر قرار دهید، زیرا ویژگیهای اصلی را حفظ میکند.
اما اگر به دنبال کاهش شدید ابعاد و ایجاد ویژگیهای جدید هستید، استخراج ویژگی مفیدتر است.
همچنین باید به اندازه مجموعه داده ، وجود نویز ، توان محاسباتی موجود و هدف نهایی (مانند تجسم دادهها یا بهبود عملکرد مدل) توجه کنید. در نهایت، ممکن است نیاز باشد چندین روش را آزمایش و مقایسه کنید تا بهترین روش برای مسئله خاص خود را بیابید.







