
مقدمه
در دنیای پرشتاب هوش مصنوعی، پردازش زبان طبیعی یا Natural Language Processing که به اختصار به آن NLP میگوییم، یک انقلاب در تعامل انسان و کامپیوتر است. پردازش زبان طبیعی به عنوان سنگ بنای هوش مصنوعی، ماشینها را قادر میسازد تا زبان انسانی را با دقت و ظرافت بیسابقهای درک، تفسیر و تولید کنند. پیامدهای آن عمیق است و همه جنبه های زندگی ما را تحت تأثیر قرار میدهد.
پردازش زبان طبیعی حالا بیش از هر زمان دیگری زبان کامپیوترها و انسانها را به هم نزدیک کرده است. در واقع دیگر شاید برای ارتباط با این ماشینهای خشک و بی روح نیاز به برنامه نویسیها نداشته باشیم. شاید حتی این فناوری به کلی ساختار دنیای کامپیوتر و حتی صنعت و شکل کامپیوتر و موبایلها و کل دنیای دیجیتال را تغییر دهد. شاید بتوان گفت پردازش زبان طبیعی که ما امروزه در ابتدای آن هستیم، تنها یک فناوری نیست. یک تغییر پارادایم بزرگ در سبک زندگی بشر است.
پردازش زبان طبیعی چیست؟
پردازش زبان طبیعی یا NLP یک زیرشاخه پیچیده از هوش مصنوعی (برای آشنایی با فناوری هوش مصنوعی و زیرشاخههای آن اینجا کلیک کنید.) است که بر تعامل بین رایانه و انسان از طریق زبان طبیعی تمرکز دارد. پردازش زبان طبیعی به دنبال این است که ماشینها زبان انسانی را به شکل معنادار و مفیدی درک کنند، تفسیر کنند و و سپس باز تولید کنند. این شامل ترکیبی از زبانشناسی محاسباتی و یادگیری ماشینی است که به مدلها اجازه میدهد از مجموعه دادههای بزرگ یاد بگیرند و با آنها سازگار شوند.
پردازش زبان طبیعی طیف گستردهای از وظایف و چالشها را در بر میگیرد که هر کدام جنبههای مختلف درک و تولید زبان را مورد توجه قرار می دهد. این وظایف شامل تجزیه نحوی است که شامل تجزیه و تحلیل ساختار دستوری جملات میشود. تحلیل معنایی، که بر درک معنای کلمات و جملات تمرکز دارد. و تحلیل عملی، که زمینه و هدف پشت استفاده از زبان را در نظر میگیرد.
علاوه بر این، پردازش زبان طبیعی شامل پردازش مجموعههای بزرگ متن برای شناسایی الگوها، احساسات، و موجودیتها میشود و در نتیجه برنامههایی مانند ترجمه ماشینی، تجزیه و تحلیل احساسات و استخراج اطلاعات را ممکن میسازد.
پردازش زبان طبیعی چگونه کار میکند؟
همانطور که گفتیم پردازش زبان طبیعی به کامپیوترها این امکان را میدهد که زبان انسان را درک و پردازش کنند. وقتی شما صحبت میکنید یا سوالی را تایپ میکنید، NLP آن را به بخشهای کوچکتر تقسیم میکند تا ساختار و معنای آن را تجزیه و تحلیل کند. از الگوریتمهایی برای درک دستور زبان، زمینه و احساس پیام استفاده میکند، سپس مرتبطترین پاسخ یا عمل را جستجو میکند. در نهایت، پاسخی را ایجاد میکند که برای شما منطقی است و تجربهای را ایجاد میکند که شبیه تعامل با شخص دیگری است.
گام به گام: پردازش زبان طبیعی چگونه کار می کند
توکن سازی
توکن سازی یا Tokenization مرحله پایهای در پردازش زبان طبیعی است که در آن متن به واحدهای کوچکتر به نام توکن تقسیم میشود. این توکنها میتوانند کلمات، عبارات یا حتی حروف باشند. هدف اصلی توکنسازی، تجزیه متن پیچیده به قطعات قابل مدیریت است که میتوان آنها را بیشتر تحلیل کرد. این مرحله بسیار مهم است زیرا فرآیندهای بعدی مانند تجزیه و برچسب گذاری بخشی از گفتار را آسانتر میکند.
اگر بخواهیم توکن سازی را سادهتر درک کنیم،بهتر است اولین روزهایی که میخواستید زبان انگلیسی را یاد بگیریدبه خاطر بیاورید، احتمالا وقتی یک جمله را میخواندیم، آن را کلمه به کلمه معنی میکردیم، در ذهن بررسی میکردیم و در نهایت معنی جمله را میفهمیدیم، توکنسازی حالا تقریبا کاری مثل همین را انجام میدهد.

مثلا وقتی Chat GPT جمله « من ایران را دوست دارم.» میبیند، آن را به توکنهای «من»، «ایران»، «را»، «دوست»، «دارم» و «.» تقسیم میکند. حتی آن نقطه هم یک توکن است زیرا اگر نقطه به علامت سوال تبدیل شود همه چیز تغییر میکند. این سیستم اجازه میدهد تا هر بخش به صورت جداگانه پردازش شود و در ک و تجزیه و تحلیل ساختار جمله ساده تر شود.
تجزیه (تحلیل نحوی)
تجزیه شامل تجزیه و تحلیل ساختار دستوری یک جمله است. این مرحله روابط بین کلمات را مشخص میکند. مثلا تعیین میکند که کدام کلمات به عنوان فاعل، فعل، مفعول و غیره عمل میکنند. تجزیه به درک ماهیت سلسله مراتبی زبان کمک میکند، که برای تفسیر دقیق معنای جملات پیچیده ضروری است.
دو نوع اصلی تجزیه وجود دارد: تجزیه نحوی ( syntactic parsing)، که بر دستور زبان تمرکز دارد، و تجزیه معنایی (semantic parsing)، که هدف آن درک معنای منتقل شده توسط ساختار دستوری است. تجزیه دقیق برای بسیاری از برنامه های پردازش زبان طبیعی، از جمله ترجمه ماشینی و تجزیه و تحلیل احساسات، حیاتی است.
مثلا جمله انگلیسی “I Love Iran” را در نظر بگیرید.
در تجزیه نحوی این جمله به صورت درختی تجزیه میشود تا نقش تک تک کلمات مشخص شود. در شکل زیر این فرآیند به شکلی ساده نمایش داده شده است.
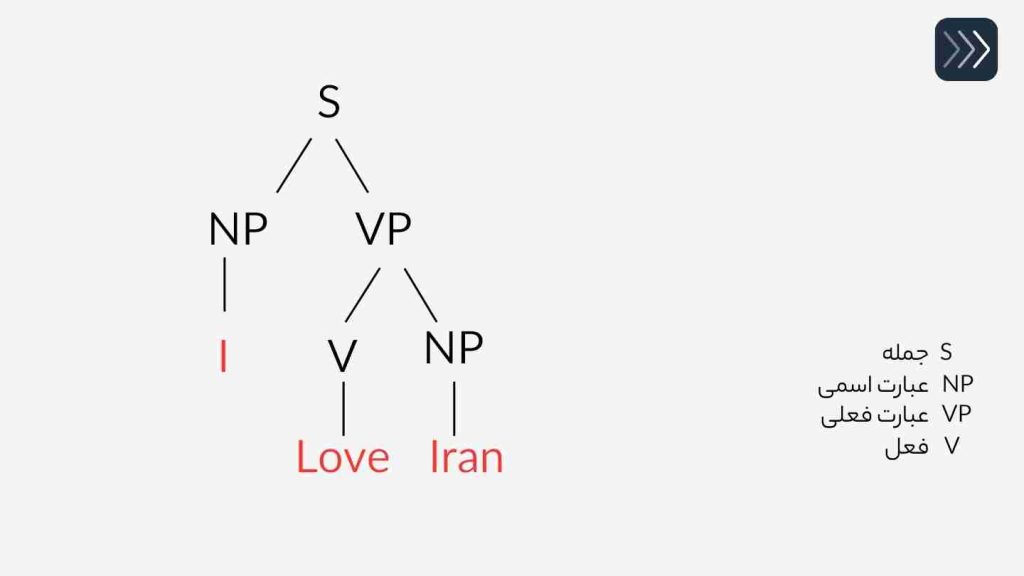
در تجزیه معنایی به معنا و ارتباط میان سازندگان جمله پرداخته میشود. به عنوان مثال در جمله ” I Love Iran” عبارت “I” به عنوان یک ضمیر که گوینده است شناسایی میشود. عبارت “Love” به عنوان یک احساس و عبارت “Iran” به عنوان یک کشور شناخته میشود و سپس با توجه به ارتباطات میان اینها، ماشین میفهمد که جمله نشان دهنده احساس دوست داشتنی است که گوینده نسبت به کشور ایران دارد.
Lemmatization و Stemming
Lemmatization (بن واژه سازی) و stemming (ریشه یابی) تکنیکهایی هستند که برای کاهش کلمات به شکل پایه یا ریشه آنها استفاده می شود. stemming شامل بریدن انتهای کلمات برای تبدیل آنها به شکل ریشه است که اغلب منجر به کلمات غیر استاندارد می شود. از سوی دیگر، Lemmatization با در نظر گرفتن زمینه و بخشی از گفتار، کلمات را به شکل متعارف خود (lemma یا بنواژه) تقلیل میدهد و در نتیجه نتایج دقیقتر و معنیداری ارائه میدهد.
این فرآیندها برای استانداردسازی کلمات قبل از تجزیه و تحلیل بیشتر ضروری هستند و اطمینان حاصل میکنند که تغییرات یک کلمه به عنوان یک مورد واحد در نظر گرفته می شود.
مثلا کلمات “Loves” و “love” را در نظر بگیرید. Stemming این موارد را به ترتیب به “love” و “love” تبدیل میکند. با این حال، Lemmatization، با در نظر گرفتن زمینه و قواعد دستوری، هر دو کلمه را به شکل پایه «Love» تبدیل میکند. این فرآیند به تجزیه و تحلیل مداوم متن، به ویژه در کارهایی مانند طبقه بندی متن و بازیابی اطلاعات، کمک میکند.

برچسب گذاری بخشی از گفتار
تگگذاری یا برجسب گذاری بخشی از گفتار یا Part-of-Speech (POS) tagging، بخشی از گفتار را به هر کلمه در یک جمله اختصاص میدهد، مانند اسم، فعل، صفت و غیره. این مرحله برای درک ساختار نحوی و معنای جملات بسیار مهم است، زیرا نقش هر کلمه را مشخص میکند.
سیستمهای پیشرفته پردازش زبان طبیعی از الگوریتمهای یادگیری ماشینی استفاده میکنند که بر روی مجموعههای بزرگی از متن برچسبگذاری شده آموزش دیدهاند تا دقت این فرآیند را بیشتر کنند، که برای کارهای بعدی مانند تجزیه و تحلیل معنایی ضروری است.
مثلا در در جمله ” I Love Iran”، برچسب گذاری بخشی از گفتار عبارت I را به عنوان ضمیر و کلمه Love را به عنوان فعل و Iran را به عنوان یک اسم مشخص میکند. این برچسب گذاری دقیق به درک ساختار دستوری و معنای جمله کمک بسیاری میکند و پردازش دقیق زبان را سادهتر میکند.
شناسایی موجودیتهای نامدار (NER)
شناسایی موجودیتهای نامدار یا Named Entity Recognition که به اختصار NER نامیده میشود، تکنیکی است که برای شناسایی و طبقه بندی عناصر کلیدی درون متن به دستههای از پیش تعریف شده مانند نام افراد، سازمانها، مکانها، تاریخها و موارد دیگر استفاده میشود.
NER برای استخراج اطلاعات معنی دار از متن بدون ساختار بسیار مهم است و به طور گسترده در برنامههایی مانند بازیابی اطلاعات، پاسخ به سؤال و طبقهبندی محتوا استفاده میشود. چالش در NER در شناسایی دقیق موجودیتها با وجود تفاوت در نام ها، اختصارات و زمینهها نهفته است. سیستمهای NER مدرن از مدلهای یادگیری عمیق آموزشدیده بر روی مجموعه دادههای گسترده برای بهبود دقت و یادآوری در شناسایی موجودیتهای نامدار استفاده میکنند.
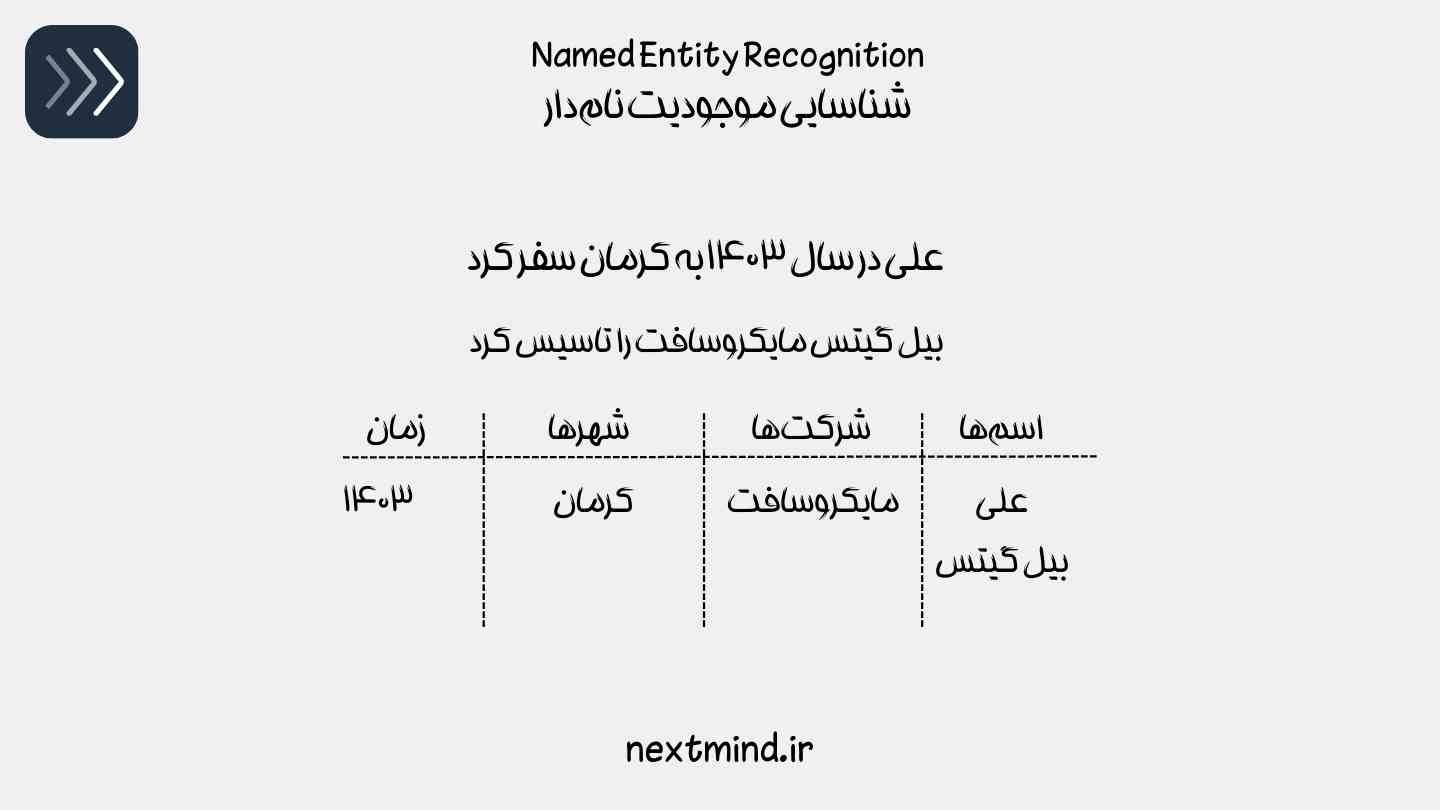
مثلا عبارت « علی در سال ۱۴۰۳ به کرمان سفر کرد» را در نظر بگیرید، سیستم «علی» را به عنوان یک شخص، «۱۴۰۳» را به عنوان تاریخ و «کرمان» را به عنوان یک مکان شناسایی میکند.
تحلیل احساسات
تحلیل احساسات شامل تعیین لحن عاطفی متن، طبقه بندی آن به عنوان مثبت، منفی یا خنثی است. این تجزیه و تحلیل برای درک افکار عمومی، بازخورد مشتریان و نظرات مردم در شبکههای بسیار مهم است. تجزیه و تحلیل احساسات از تکنیک های مختلف، نظیر رویکردهای ساده مبتنی بر قوانین گرفته تا الگوریتمهای پیچیده یادگیری ماشین، برای ارزیابی احساسات منتقل شده توسط کلمات، عبارات و زمینه کلی متن استفاده میکند. چالشی که در این بخش وجود دارد طعنهها و کنایهها و این مدل جملات است.
همان جمله « من ایران را دوست دارم» را در نظر بگیرید. تحلیل احساسات متن را به دلیل وجود کلماتی مانند “دوست داشتن” به عنوان مثبت طبقهبندی می کند.
ترجمه ماشینی
ترجمه ماشینی متن را با استفاده از الگوریتم های پردازش زبان طبیعی از یک زبان به زبان دیگر ترجمه میکند میکند. این فرآیند شامل درک متن مبدأ، نگاشت معنای آن به زبان مقصد، و تولید ترجمههای دقیق دستوری و متنی است. سیستمهای ترجمه ماشینی مدرن از شبکههای عصبی، بهویژه مدلهای ترانسفورماتور مانند ترانسفورماتر گوگل و GPT شرکت OpenAI برای دستیابی به سطوح بالایی از دقت و روانی ترجمه استفاده میکنند. این مدلها بر روی مجموعه دادههای چندزبانه عظیم آموزش داده شدهاند و آنها را قادر میسازد تا تفاوتهای ظریف و عبارات اصطلاحی را در سراسر زبانها مدیریت کنند.
تولید زبان
تولید زبان یا Language generation شامل ایجاد متن منسجم و مرتبط با زمینه از دادههای داده شده است. این فرآیند برای برنامههایی مانند چتباتها، ایجاد خودکار محتوا و خلاصه سازی ضروری است. سیستمهای تولید زبان از مدلهایی استفاده میکنند که بر روی مجموعههای بزرگی از متن آموزش داده شدهاند تا پاسخهایی شبیه انسان ایجاد کنند.
درک متنی
درک متنی توانایی یک سیستم پردازش زبان طبیعی برای درک زمینه وسیعتری است که در آن کلمات و عبارات استفاده میشود. این شامل شناخت روابط بین بخشهای مختلف متن و درک چگونگی تأثیر متن بر معنا است. مدلهای پیشرفته مانند ترانسفورماتورها از مکانیسمهای توجه به خود برای ثبت وابستگیها و زمینههای دوربرد در متن استفاده میکنند و پردازش زبان دقیقتر را امکان پذیر میکنند. درک متنی برای کارهایی مانند ابهام زدایی، تفکیک همبستگی و استنتاج زبان طبیعی ضروری است.
تولید پاسخ
تولید پاسخ آخرین مرحله درپردازش زبان طبیعی است که در آن سیستم یک پاسخ منسجم و مرتبط با زمینه را بر اساس ورودی پردازش شده ایجاد میکند. این شامل ترکیب اطلاعات از مراحل قبلی برای ایجاد یک پاسخ طبیعی و معنادار است. مدلهای تولید پاسخ، مانند مدلهای مبتنی بر GPT، از پیشآموزش و تنظیم دقیق در مقیاس بزرگ برای تولید متنی شبیه انسان استفاده میکنند. این مدلها زمینه، هدف و تفاوتهای ظریف ورودی را برای ارائه پاسخهای مناسب و جذاب در نظر می گیرند.
این مراحلی که در بالا به صورت خلاصه بیان شد، بیشتر در چتباتها و سیستمهای تولید محتوای متنی مثل Chat GPT و Gemini و Claude و … به کار گرفته میشود اما همیشه قرار نیست پردازش زبان طبیعی همه این موارد یا فقط همین موارد را داشته باشد. مثلا در سیستمهای تولید عکس با هوش مصنوعی، ابتدا ما متن را مینویسیم، ابتدا پردازش زبان طبیعی صورت میگیرد اما از جایی مدلهای دیگر هوش مصنوعی مشغول به کار میشوند و برای شما تصویر میسازند نه این که به تولید پاسخ متنی بپردازند. بر حسب کاربرد این مراحل متفاوت میتواند باشد اما در کاملترین رویه که پردازش زبان طبیعی در چتباتها و … است مراحل بالا به صورت کلی دیده میشود.
کاربردهای پردازش زبان طبیعی
پردازش زبان طبیعی به صورت مستقیم هرجایی که با متن و زبان در ارتباط باشد را متحول میکند و بسیاری از حوزهها را هم به صورت غیر مستقیم دستخوش تغییر میکند. در ادامه برخی از کاربردهای پردازش زبان طبیعی را با هم بررسی میکنیم.
ترجمه متن
همه ما از گوگل ترنسلیت استفاده کردهایم، گوگل ترنسلیت، مایکروسافت ترنسلیت، هوش مصنوعی DeepL همه از پردازش زبان طبیعی برای ترجمه متن و نوشتهها استفاده میکنند. پردازش زبان طبیعی به پشتوانه روشهای پیشرفته یادگیری عمیق امروزه به ما اجازه میدهد هر متنی را از هر زبانی به زبان دیگر به راحتی ترجمه کنیم. علاوه بر اینها بسیاری از سیستمهای مترجم صوتی نیز در ابتدا با تشخیص گفتار، متن را بدست میآورند و سپس با استفاده از پردازش زبان طبیعی در لحظه ترجمه میکنند و حتی بعد میتوانند با صدای مخاطب شما آن را به زبان مد نظر شما بخوانند.
بدون شک کاربردهای هوش مصنوعی و پردازش زبان طبیعی در حوزه ترجمه میتواند زمینهساز تغییرات بزرگی شود. تصور کنید دنیایی را که شما دیگر نیاز به یادگیری زبانهای دیگر نداشته باشید و بتوانید همه زبانها را بفهمید و صحبت کنید. هوش مصنوعی این موضوع را برای شما امکان پذیر میکند.

دستیارهای مجازی
دستیارهای مجازی مانند آمازون الکسا، Siri و دستیار گوگل از پردازش زبان طبیعی برای تفسیر و پاسخگویی به سوالات کاربران استفاده میکنند. این سیستمها از تشخیص گفتار، درک زبان طبیعی و تولید پاسخ برای ارائه اطلاعات، انجام وظایف و کنترل دستگاههای خانه هوشمند استفاده میکنند. شاید تا به حال این دستیار ها فقط بر روی موبایل یا لپتاپ شما بودهاند اما شاید به زودی شما حتی با ماشین لباسشویی خانهتان هم حرف بزنید و به زبان خودتان به او بگویید که لباسهایتان را چطور بشوید. پردازش زبان طبیعی ارتباط انسان و ماشین را واقعا متحول خواهد کرد.
چتباتها
چتباتهای معروفی که در همین یکی دو سال اخیر معرفی شدند همگی از پردازش زبان طبیعی استفاده میکنند. این چت باتها میتوانند متن شما یا حتی صدای شما را درک کنند، تفسیر کنند و به شما پاسخ دهند یا حتی با برای شما مقالات علمی تولید کنند. نه فقط چتباتها بلکه سرویسهای ساخت عکس از متن یا ساخت ویدئو از متن و … همگی در بخشی از فعالیتهای خود از پردازش زبان طبیعی استفاده میکنند. کلا هرجا که کامپیوتر میفهمد شما چه میگویید پردازش زبان طبیعی وجود دارد.
تحلیل احساسات
تجزیه و تحلیل احساسات، لحن احساسی متن را تعیین میکند. این کاربرد برای کسب و کارها برای درک نظرات و بازخورد مشتریان بسیار مهم است. این فناوری به طور گسترده در نظارت بر رسانههای اجتماعی، مدیریت برند و تحقیقات بازار استفاده می شود. با تجزیه و تحلیل نظرات، نظرات و پستهای رسانههای اجتماعی، شرکتها میتوانند احساسات عمومی را بسنجند، محصولات و خدمات را بهبود ببخشند و تصمیمات تجاری آگاهانه بگیرند. مثلا شما میتوانید بررسی کنید که نظرات مردم در مورد انتخابات چگونه است، پردازش زبان طبیعی با رصد کردن و تحلیل توییتها میتواند به سادگی این موضوع را برای شما تحلیل کند.
ساخت محتوا
حوزه ساخت محتوا حوزه بسیار گستردهای است و طیف وسیعی از کاربردها را شامل میشود و ما اینجا همه آنها را با هم و به صورت یک دسته به شما معرفی میکنیم. مثلا سیستمهایی که متنی به آنها میدهید و برای شما یک خلاصه مینویسند، یا هوش مصنوعیهایی مانند Rytr که به صورت تخصصی متن برای وبسایت شما درست میکنند یا حتی پلتفرمی مثل Stack AI که به سازمان شما این اجازه را می دهد بر اساس دادههای سازمانی خود گزارشها و نامهها را بنویسید، همگی از پردازش زبان طبیعی استفاده میکنند. تقریبا پردازش زبان طبیعی حوزهای است که همه انسانها به طریقی با آن در ارتباط هستند.
خدمات مشتری
همانگونه که گفتیم چتباتها یکی از کاربردهای پردازش زبان طبیعی هستند، این چتباتها فقط در وبسایتهای بزرگ نظیر Chat GPT نیستند. امروزه بسیاری از شرکتها با استفاده از دادههای خود، بخش خدمات مشتریان را به هوش مصنوعی سپردهاند. این هوش مصنوعی میتواند مشتریان را راهنمایی کند، به آنها محصولات مناسبشان را معرفی کند و هر سوالی که دارند را پاسخ دهد.
پردازش زبان طبیعی در حوزه سلامت
پردازش زبان طبیعی برای استخراج اطلاعات با ارزش از یادداشت های بالینی، مقالات تحقیقاتی و سوابق بیمار استفاده می شود و به تشخیص و درمان بهتر کمک می کند. حالا پزشکان میتوانند تمامی سوابق بیمار را به راحتی و خلاصه بررسی کنند و بر اساس آنها به تجویز دارو و تعیین روش درمانی اقدام کنند.
پردازش زبان طبیعی در حوزه آموزش و یادگیری
شما با استفاده از هوش مصنوعی زبان انگلیسی یاد میگیرید؟ یا از معلمهایی اسفاده میکنید که به سوالات شما پاسخ میدهند اما وجود خارجی ندارد؟ همه اینها با پردازش زبان طبیعی سرو کار دارند. یکی از ابزارهایی که بسیاری از ما با آن آشنا هستیم ابزار گرامرلی است که برای بهبود و اصلاح نوشتههای خودمان از آن استفاده میکنیم. در اینجا نیز پردازش زبان طبیعی است که دارد به ما یاد میدهد چگونه بنویسیم بهتر است.
پردازش زبان طبیعی کاربردهای بسیار بسیار زیادی دارد. احتمالا روز به روز هم کاربردهای آن بیشتر شود و شاید روزی با تمام ماشینها و ابزارهای اطرافمان و حتی آدمهایی که زبان ما را بلد نیستند، با زبان خودمان صحبت کنیم.
تاریخچه پردازش زبان طبیعی
پردازش زبان طبیعی قدمتی به اندازه خود مفهوم هوش مصنوعی دارد. در ادامه به صورت کوتاه و مختصر این تاریخچه و روند تکامل را بررسی میکنیم.
آغاز پردازش زبان طبیعی در دهه ۱۹۵۰
ریشههای پردازش زبان طبیعی یا NLP را میتوان در دهه 1950 میلادی ردیابی کرد، زمانی که آلن تورینگ پایههای نظری را برای هوش ماشینی ایجاد کردند( برای آشنایی کامل با تاریخچه هوش مصنوعی اینجا کلیک کنید). تقریباً در همان زمان، تلاشهای اولیه در حوزه ترجمه ماشینی در حال انجام بود، با آزمایشGeorgetown-IBM در سال 1954 که با موفقیت بیش از شصت جمله روسی را به انگلیسی ترجمه کرد و یکی از اولین کاربردهای عملی پردازش زبان طبیعی را نشان داد.
سیستمهای مبتنی بر قانون
دهه های 1960 و 1970 با توسعه سیستمهای مبتنی بر قانون شاهد پیشرفتهای چشمگیری بودیم. محققان بر روی ایجاد مجموعههای گستردهای از قوانین دستور زبان تمرکز کردند تا ماشینها بتوانند زبان را تجزیه و درک کنند. یکی از پروژههای قابل توجه این دوره SHRDLU بود یک برنامه درک زبان طبیعی اولیه است که توسط تری وینوگراد در MIT توسعه یافت. SHRDLU میتوانست اشیاء را در دنیای مجازی با استفاده از دستورات انگلیسی دستکاری کند. علیرغم این پیشرفتها، محدودیتهای سیستمهای مبتنی بر قاعده آشکار شد. زیرا زبان انسانی بسیار بسیار پیچیدهتر از چیزی است که با این قوانین بتوان آن را درک کرد.
ظهور روشهای آماری
دهههای 1980 و 1990 با معرفی روشهای آماری در پردازش زبان طبیعی،همه چیز عوض شد. محققان شروع به استفاده از مجموعههای بزرگی از متن و مدلهای آماری برای بهبود درک و تولید زبان کردند. ظهور تکنیکهای یادگیری ماشین، بهویژه مدلهای مارکوف پنهان (HMM) و بعد از آن، ماشینهای بردار پشتیبان (SVM)، وظایفی مانند برچسبگذاری بخشی از گفتار و شناسایی موجودیت نامگذاری شده را بهطور قابلتوجهی افزایش داد. این دوره همچنین شاهد توسعه سیستمهای تشخیص گفتار اولیه بود که پایه و اساس کاربردهای پیچیدهتر را ایجاد کرد.
انقلاب یادگیری عمیق
قرن بیست و یکم با ظهور یادگیری عمیق انقلابی در پردازش زبان طبیعی به وجود آورد. در دهه ۲۰۱۰، معرفی شبکههای عصبی، بهویژه شبکههای عصبی بازگشتی (RNN) و شبکههای عصبی کانولوشنال (CNN) این حوزه را متحول کرد. راه اندازی معماری ترانسفورماتور در سال 2017 و به دنبال آن مدلهایی مانند BERT (نمایش رمزگذار دوطرفه از ترانسفورماتورها) و GPT (ترانسفورماتور از پیش آموزش دیده مولد)، مرزهای پردازش زبان طبیعی را گستراند. این مدلها به سطوح بیسابقهای از دقت و روانی در کارهایی مانند ترجمه ماشینی، تولید متن و تحلیل احساسات دست یافتند. حالا همه ما حاصل زحمات و تلاشهای بیش از ۷۰ سال را در استفاده روز مرده از سیستمهای هوش مصنوعی لمس میکنیم و چیزی که مطمئن هستیم این است که این تازه ابتدای ماجرا است.
سفر NLP در دهه 1950 با ظهور زبان شناسی محاسباتی آغاز شد. تلاشهای اولیه ابتدایی بودند و شامل سیستمهای مبتنی بر قوانین ساده بودند. در طول دههها، پیشرفتها در یادگیری ماشین، بهویژه یادگیری عمیق، NLP را متحول کرده و آن را قویتر و توانمندتر کرده است.
چالش های پردازش زبان طبیعی
با وجود این که امروز به راحتی کامپیوترها حرف ما را میفهمند اما حوزه پردازش زبان طبیعی چالشهایی دارد که باید به آنها پرداخته شود. مدیریت زمینه و ابهام و همچنین بحث اخلاق از جمله این چالشها است.
مدیریت زمینه و ابهام
پردازش زبان طبیعی هنوز هم با پیچیدگی و ابهام ذاتی زبان انسان دست و پنجه نرم میکند. واقعیت این است که زبان صرفا از دستورات و معانی واقعی کلمات پیروی نمیکند. انسانها با کنایه و شوخی و طعنه با یک دیگر صحبت میکنند که این موضوع برای ماشین ها هنوز هم یک چالش بزرگ است. ما گاهی یک عبارت را دقیقا به معنای برعکس به کار میبریم. مثلا گاهی که دوستمان اشتباهی انجام میدهد میگوییم « دست شما درد نکند»، یا مثلا ممکن است وقتی کسی حرف بدی به ما میزند بگوییم« مچکرم». این پیچیدگیها همچنان برای هوش مصنوعی قابل تشخیص نیست.
استفاده اخلاقی و مسئولانه از هوش مصنوعی
احتمالا بارها دیدهاید که برخی از افراد از روی سادهلوحی فریب حرفهای دیگران را میخورند. مثلا میتوان با دروغی حرفهای آنها را متقاعد کرد که کاری را انجام دهند. یا مثلا در بسیاری از مواقع کودکان را فریب میدهند، در واقع کودک یا شخص ساده لوح میتواند زبان و حرف را بفهمد و کار را انجام دهد، اما قدرت این که استدلال کند واقعا آیا شخص راست میگوید یا انجام این کار درست است را ندارد.
هوش مصنوعی هم همین است، شاید بتواند با پردازش زبان طبیعی حرف انسان را بفهمد اما انسان در حال حاضر میتواند او را فریب دهد و استفادههای غیر اخلاقی از آن بکند. همین موضوع باعث شده است که موضوع استفاده اخلاقی و مسئولانه از هوش مصنوعی به یک چالش جدی تبدیل شود. مثلا همانطور که در معرفی هوش مصنوعی Claude گفتیم، این شرکت بسیار به اخلاقیان توجه کرده است تا یک هوش مصنوعی مفید خلق کنند.
آینده پردازش زبان طبیعی
آینده پردازش زبان طبیعی نوید پیشرفت های قابل توجهی را می دهد که توسط تحقیقات مداوم و ادغام فناوریهای پیشرفته هدایت میشود. یکی از تأثیرگذارترین روندها، توسعه مدلهای پیچیدهتر آگاه از زمینه (context-aware) است. سیستمهای پردازش زبان طبیعی آینده احتمالاً معماریهای عصبی پیشرفتهای مانند ترانسفورماتورها و مکانیسمهای توجه را برای افزایش توانایی خود در درک و تولید متنهای انسانمانند در خود خواهند داشت.

این مدلها بر روی مجموعه دادههای متنوع و جامعتر آموزش داده میشوند و عملکردشان را در زبانها، گویشها و زمینههای فرهنگی مختلف بهبود میبخشند. این تکامل درک زبان دقیقتر و ظریفتری را به هوش مصنوهی میدهد، تعاملات انسان و ماشین را تسهیل میکند و امکانهای جدیدی را در زمینههایی مانند تولید محتوای خودکار، ترجمه بلادرنگ و هوش مصنوعی محاورهای باز میکند.
روند مهم دیگری که آینده پردازش زبان طبیعی را شکل میدهد، تأکید بر هوش مصنوعی اخلاقی و استقرار مسئولانه است. همانطور که فناوریهای NLP قدرتمندتر گستردهتر میشوند، رسیدگی به مسائل مربوط به سوگیری، حریم خصوصی و اطلاعات نادرست بسیار مهم خواهد بود. محققان و متخصصان بر روی توسعه چارچوبها و دستورالعملهای قوی برای اطمینان از استفاده عادلانه و شفاف از سیستم های NLP تمرکز خواهند کرد.
این شامل ایجاد روش هایی برای شناسایی و کاهش سوگیری ها، اجرای اقدامات سختگیرانه حفاظت از دادهها، و ترویج استفاده اخلاقی از محتوای تولید شده توسط هوش مصنوعی است. علاوه بر این، همکاریهای بین رشتهای با ترکیب بینشهای زبانشناسی، علوم شناختی و علوم اجتماعی برای ایجاد برنامههای کاربردی NLP با محوریت انسانمحور و اخلاقی بیشتر رایجتر خواهند شد. این تلاشها به تقویت اعتماد عمومی کمک میکند و به پیشرفت مسئولانه فناوری پردازش زبانط بیعی کمک میکند و به ما این اطمینان را میدهد که بالاخره همه جامعه نفع خواهند برد.
حرف آخر
پردازش زبان طبیعی یک فناوری تحول آفرین با پیامدهای گسترده است. NLP از تقویت تعاملات انسان و رایانه گرفته تا خودکارسازی وظایف پیچیده، راه را برای آینده دیجیتالی شهودیتر و هوشمندانهتر هموار میکند. با ادامه پیشرفت تحقیق و توسعه، میتوانیم انتظار تعاملات پیچیدهتر و شبیه انسان را با ماشینها داشته باشیم.
با درک مبانی، مکانیک و کاربردهای NLP، ما به یکی از جذابترین حوزههای هوش مصنوعی، هدایت نوآوری در سراسر صنایع و تغییر شکل تعامل خود با فناوری، بینشی به دست میآوریم.







