
بنچمارکها ابزار مهمی برای ارزیابی عملکرد مدلهای هوش مصنوعی هستند. این آزمونها نشان میدهند که یک مدل در چه حوزههایی قوی است و در کجا ضعف دارد. محققان از بنچمارکها برای مقایسه مدلها و بهبود آنها استفاده میکنند.
در سالهای اخیر، مدلهای زبانی بزرگ پیشرفت زیادی کردهاند. این مدلها توانایی بالایی در پردازش زبان طبیعی دارند. اما برای سنجش دقیقتر آنها، به آزمونهای سختتر نیاز داریم. “آزمون نهایی بشریت” (Humanity’s Last Exam) یکی از پیچیدهترین و سختترین بنچمارکهای جدید است که حتی بسیاری از مدلها جرئت وارد شدن به آن را ندارند. در این مقاله به معرفی و بررسی بنجمارک Humanity’s Last Exam یا آخرین آزمون بشریت میپردازیم.
آشنایی با بنچمارک «آخرین آزمون بشریت»
«آخرین آزمون بشریت» یک بنچمارک جدید برای سنجش توانایی مدلهای هوش مصنوعی است. این آزمون را مرکز ایمنی هوش مصنوعی (CAIS) و شرکت Scale AI طراحی کردهاند. هدف از این آزمون، بررسی مهارتهای پیشرفته هوش مصنوعی در حل مسائل پیچیده است. برخلاف بسیاری از بنچمارکهای قبلی، این آزمون فقط بر مهارتهای زبانی تمرکز ندارد. مدلهای هوش مصنوعی برای موفقیت در این آزمون باید استدلال کنند، مفاهیم علمی را درک کنند و مسائل ریاضی را حل کنند.
از نظر میزان سختی، این بنچمارک به قدری دشوار است که نتایج آن را میتوان به عنوان معیاری برای رسیدن به هوش مصنوعی جنرال یا همان AGI در نظر گرفت.
برای به چالش کشیدن مدلهای هوش مصنوعی،۳۰۰۰ سوال فوقالعاده سخت، توسط بیش از ۱۰۰۰ دانشمند (ریاضی دان، فیلسوف، مهندسین راکت و …) از ۵۰ کشور جهان، طراحی شده است. برخی از این سوالات، به قدری سخت طراحی شدهاند که هر کدام جایزه ۵ هزار دلاری داشتهاند.
ساختار و ویژگیهای سؤالات بنچمارک «آخرین آزمون بشریت»
سؤالات این بنچمارک برای ارزیابی عمیق تواناییهای مدلهای هوش مصنوعی طراحی شدهاند. برخلاف بسیاری از آزمونهای استاندارد، این سؤالات فقط به دانش عمومی متکی نیستند. مدلها باید مهارتهای تحلیلی، استدلالی و حل مسئله داشته باشند تا بتوانند به درستی پاسخ دهند.
تنوع حوزههای علمی
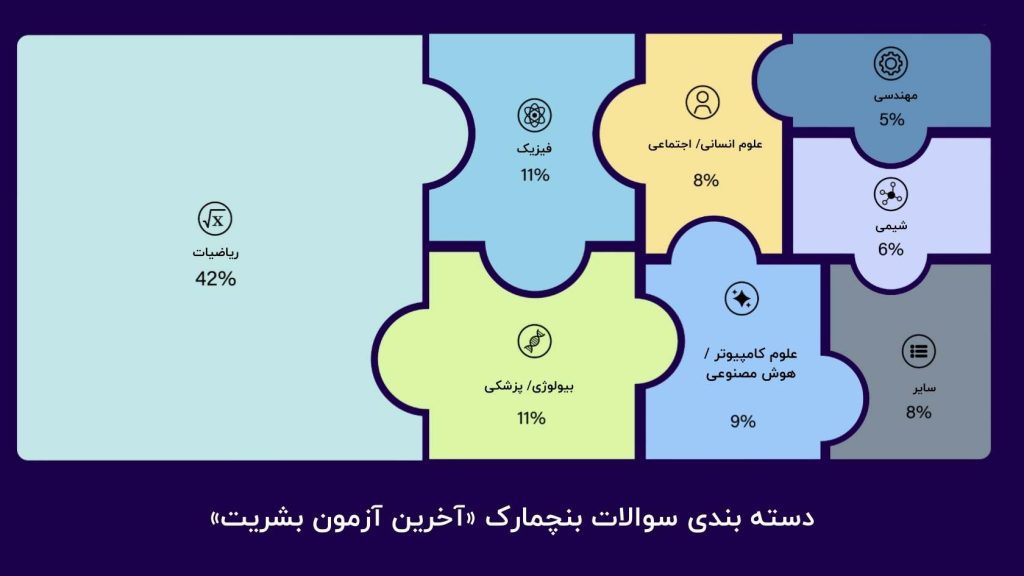
آزمون شامل ۳۰۰۰ سؤال از بیش از ۱۰۰ حوزه مختلف است. ۴۲ درصد از سؤالات مربوط به ریاضیات است، زیرا این حوزه نیازمند استدلال منطقی و توانایی حل مسئله است. سایر سؤالات به رشتههایی مانند فیزیک، زیستشناسی، مهندسی، علوم اجتماعی و علوم انسانی اختصاص دارند.
ترکیب سؤالات چندرسانهای
برخی از سؤالات فقط متنی هستند، اما بسیاری از آنها شامل نمودارها، تصاویر، جداول و دادههای عددی میشوند. مدلهای هوش مصنوعی باید این اطلاعات را تفسیر کرده و به درستی تحلیل کنند. این ویژگی، آزمون را به چالشی جدی برای مدلهای زبانی تبدیل میکند.
سطح دشواری بالا
طراحان آزمون، سؤالات را طوری طراحی کردهاند که حتی برای انسانها نیز دشوار باشند. بسیاری از پرسشها نیاز به درک عمیق مفاهیم و توانایی ترکیب اطلاعات از منابع مختلف دارند. این آزمون فقط بر اساس حفظ کردن اطلاعات ارزیابی نمیشود، بلکه بر مهارتهای استدلالی و منطقی تأکید دارد.
عدم امکان اتکا به دادههای از پیش دیدهشده
در برخی بنچمارکهای رایج، مدلهای هوش مصنوعی میتوانند به دلیل دیده شدن دادههای مشابه در مرحله آموزش، عملکرد خوبی داشته باشند. اما در «آخرین آزمون بشریت»، بسیاری از سؤالات جدید و منحصربهفرد هستند. این ویژگی باعث میشود که مدلها نتوانند صرفاً بر اساس الگوهای آماری به پاسخ صحیح برسند.
این ویژگیها باعث شده که «آخرین آزمون بشریت» یکی از سختترین بنچمارکهای هوش مصنوعی باشد. مدلهای فعلی در این آزمون عملکرد ضعیفی داشتهاند، که نشان میدهد هنوز راه زیادی تا دستیابی به هوش عمومی مصنوعی (AGI) باقی مانده است.
برخی از سوالات این بنچمارک به صورت عمومی منتشر شده است و اما برای این که از بیشبرازش یا Overfitting مدلها جلوگیری شود، برخی از سوالات نیز پنهان مانده اند.
مقایسه بنچمارک Humanity’s Last Exam (HLE) با سایر بنچمارکها
امروزه بنچمارکهای مختلفی برای سنجش و مقایسه عملکرد مدلهای هوش مصنوعی وجود دارد. پنچمارکهایی نظیر MMLU ، MATH و GPQA از معروفترین این بنچمارکها هستند. هنگامی که یک مدل هوش مصنوعی جدید وارد بازار میشود، با این بنچمارکها مورد ارزیابی قرار میگیرد. اما این بنچمارکها در مقایسه با بنچمارک HLE یا همان آخرین آزمون بشریت، تنها یک شوخی هستند.
به عنوان نمونه، در در حالی که مدل معروف GPT-4o در بنچمارکهایی نظیر MMLU امتیازی بالای ۸۰ میگیرند، در بنچمارک HLE تنها ۳.۲ امتیاز (از ۱۰۰) بدست آورده است. هوش مصنوعی Deepseek R1 در حال حاضر بیشترین امتیاز (۹.۴) را دارد. نمودار زیر، عملکرد مدلها در بنچمارکهای مختلف را نشان میدهد.
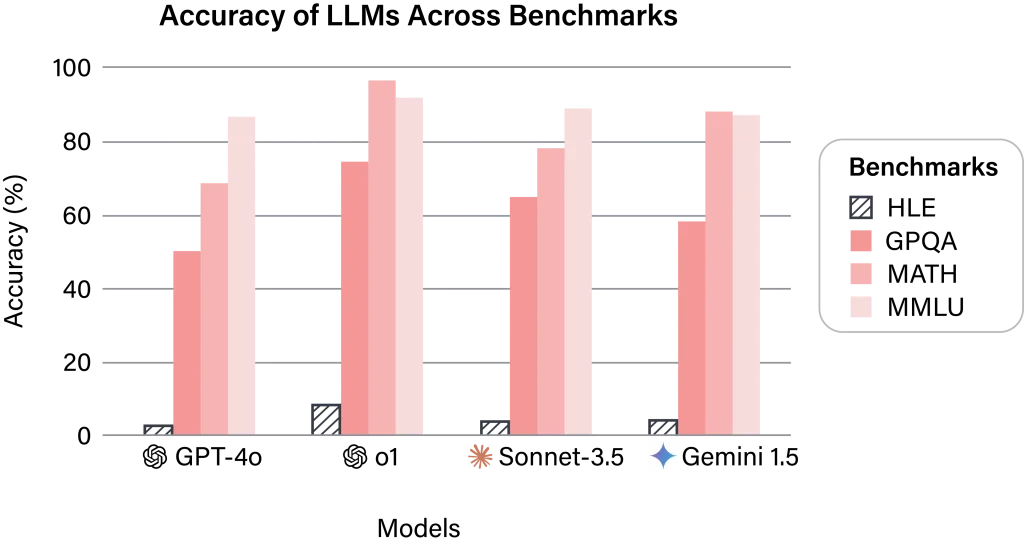
برای درک بهتر، بیایید یک مثال بزنیم. تصور کنید مدل هوش مصنوعی O1 یکی از باهوش ترین مدل هاست. او در همه امتحانهای مدرسه نمرهای زیر ۱۶ نداشته است، اما در درس آخرین آزمون بشریت، نمره او حتی ۲ هم نشده است. تازه این یکی از دانشآموزهای باهوش مدرسه است.
قویترین هوش مصنوعی در بنچمارک Humanity’s Last Exam
در حال حاضر، بهترین عملکرد در بنچمارک هیومنیتیز لست اگزم متعلق به ابزار Deep research در چت جیپیتی است. به شکلی باورنکردنی، دیپ ریسرچ توانسته است امتیاز ۲۶/۶ درصد را کسب کند که اختلاف بسیار بالایی با بقیه مدلها دارد. جدول زیر، امتیازات برخی از مدلهای هوش مصنوعی در این بنچمارک را نمایش میدهد.
| مدل | دقت (٪) |
|---|---|
| GPT-4o | 3.3 |
| Grok-2 | 3.8 |
| Claude 3.5 Sonnet | 4.3 |
| Gemini Thinking | 6.2 |
| OpenAI o1 | 9.1 |
| DeepSeek-R1 | 9.4 |
| OpenAI o3-mini (medium) | 10.5 |
| OpenAI o3-mini (high) | 13.0 |
| OpenAI deep research | 26.6 |
برخی از سوالات بنچمارک HLE
اما سوالات بنچمارک HLE مگر چقدر سخت است؟ خب بیایید یکی از سوالات آن را بررسی کنیم.
نمونه سوال فیزیک در بنچمارک آخرین آزمون بشریت
یک بلوک روی یک ریل افقی قرار گرفته است که میتواند بدون اصطکاک روی آن حرکت کند. این بلوک به انتهای یک میله صلب و بدون جرم به طول R متصل شده است. در انتهای دیگر این میله، یک جرم متصل شده است. هر دو جسم دارای وزنی برابر با W هستند.
سیستم در ابتدا ساکن است، بهطوری که جرم دقیقاً بالای بلوک قرار دارد. به این جرم یک ضربه بسیار کوچک در راستای موازی با ریل داده میشود. فرض کنید که سیستم بهگونهای طراحی شده است که میله میتواند بدون مانع یک چرخش کامل ۳۶۰ درجه انجام دهد.
وقتی میله در حالت افقی قرار دارد، نیروی کششی (تنش) آن T₁ است. زمانی که میله دوباره در حالت عمودی قرار گیرد، بهطوری که جرم مستقیماً زیر بلوک قرار بگیرد، نیروی کششی آن T₂ خواهد بود. (این مقادیر میتوانند منفی باشند، که در این صورت نشان میدهد میله تحت فشار است.)
مقدار (T₁ − T₂) / W چقدر است؟
نمونه سوال زبانشناسی در پنچمارک Humanity’s Last Exam
من متن استاندارد عبری کتاب مقدس را از Biblia Hebraica Stuttgartensia (مزمور ۱۰۴:۷) ارائه میکنم. وظیفه شما این است که بین هجاهای بسته و باز تمایز قائل شوید.
لطفاً تمامی هجاهای بسته (هجاهایی که به یک صامت ختم میشوند) را شناسایی و فهرست کنید، بر اساس جدیدترین پژوهشها درباره سنت تلفظ طبری عبری کتاب مقدس، که توسط پژوهشگرانی مانند جفری خان، آرون دی. هورنکول، کیم فیلیپس، و بنجامین سوچارد انجام شده است.
منابع قرونوسطایی، مانند نسخههای دستنویس قرائیمی، به پژوهشگران مدرن کمک کردهاند تا جنبههای خاصی از تلفظ عبری کتاب مقدس در سنت طبری را بهتر درک کنند، از جمله ویژگیها و عملکردهای شوا و اینکه کدام حروف در پایان هجاها به عنوان صامت تلفظ میشدند.
مִן־גַּעֲרָ֣תְךָ֣ יְנוּס֑וּן מִן־ק֥וֹל רַֽ֝עַמְךָ֗ יֵחָפֵזֽוּן (مزمور ۱۰۴:۷)
سوالی از شاخه زیست شناسی
مرغهای مگسخوار در راسته Apodiformes بهطور منحصربهفردی دارای یک استخوان بیضوی دوطرفه جفتشده هستند، یک استخوان سزاموئید که در بخش دمیجانبی آپونوروز متقاطع و گسترده محل اتصال عضله m. depressor caudae قرار دارد. این استخوان سزاموئید از چند تاندون جفتشده پشتیبانی میکند؟ پاسخ را به صورت یک عدد بیان کنید.
احتمالا فهمیدهاید که سوالات این بنچمارک تا چه اندازه تخصصی و حرفهای هستند. این سوالات را متخصصین و دانشمندان بزرگ جهان طراحی کردهاند. حالا تصور کنید که یک هوش مصنوعی باید در این آزمون، ۳۰۰۰ تا از این سوال ها را پاسخ دهد.
شما هم میتوانید سوالات خود را ارسال کنید
اگر احساس میکنید میتوانید سوالات سخت طراحی کنید، پس بهتر است شما هم سوالاتتان را به تیم اجرایی ارسال کنید. تا چندی پیش که جایزه همچنان پا برجا بود، ممکن بود با ارسال سوال، برنده جایزه ۵۰۰۰ دلاری شوید. اما الان خبری از جایزه نیست. اما میتوانید حسابی مدلهای هوش مصنوعی را اذیت کنید. برای ارسال سوال کافی است به وبسایت رسمی این بنچمارک سر بزنید.
چالشها و محدودیتهای بنچمارک «آخرین آزمون بشریت»
اگرچه بنچمارک «آخرین آزمون بشریت» یک معیار پیشرفته برای ارزیابی هوش مصنوعی است، اما چالشها و محدودیتهایی نیز دارد. یکی از بزرگترین مشکلات این آزمون، محدودیتهای موجود در دامنه سؤالات است. برخی از سؤالات ممکن است بهطور مستقیم بر اساس دادههای از پیش دیدهشده طراحی شوند، که این میتواند به مدلها این امکان را بدهد تا با استفاده از الگوهای آماری پاسخ دهند. همچنین، بسیاری از سؤالات نیاز به درک عمیقتر مفاهیم انسانی دارند که مدلهای هوش مصنوعی هنوز توانایی درک آنها را ندارند.
دیگر چالش مهم، عدم تطابق کامل با دنیای واقعی است. بسیاری از سؤالات این آزمون به صورت مصنوعی و در محیطهای کنترلشده طراحی شدهاند، که ممکن است باعث شود مدلها نتوانند در موقعیتهای واقعی و پیچیدهتر عملکرد خوبی نشان دهند. علاوه بر این، هزینههای بالای طراحی و اجرا برای توسعهدهندگان بنچمارک و مدلهای هوش مصنوعی، یک محدودیت قابل توجه است. این آزمونها ممکن است تنها در شرایط خاصی و برای مدلهای بسیار پیشرفته انجام شوند، که باعث محدودیت در دسترس بودن آنها برای ارزیابی عمومی میشود.
آینده بنچمارک «آخرین آزمون بشریت»
بنچمارک آخرین آزمون بشریت به عنوان یک ابزار ارزیابی پیشرفته، آینده روشنی دارد. نتایج آن به محققان کمک میکند تا نقاط ضعف مدلهای هوش مصنوعی را شناسایی کرده و بهبود بخشند. در آینده، این آزمون ممکن است سؤالات پیچیدهتر و متنوعتری در حوزههای مختلف اضافه کند تا به چالشهای بیشتری برای مدلها تبدیل شود. همچنین، مدلهای هوش مصنوعی با گذشت زمان ممکن است تواناییهای استدلالی و تحلیلی بهتری پیدا کنند و به سطحی نزدیکتر به هوش عمومی مصنوعی (AGI) برسند.
این بنچمارک میتواند به عنوان معیاری برای ارزیابی پیشرفت به سمت AGI استفاده شود. اگر مدلی بتواند در این آزمون موفقیت نسبی به دست آورد، احتمالاً به تواناییهای هوش انسانی نزدیک شده است. علاوه بر این، آخرین آزمون بشریت میتواند در ارزیابی خطرات مرتبط با AGI و کمک به سیاستگذاران در تدوین مقررات هوش مصنوعی نقش مهمی ایفا کند.





