

















فیسبوک با لاما میآیند
هوش مصنوعی Llama امروزه یکی از معروفترین هوش مصنوعیهای جهان است. احتمالا بارها کلمه هوش مصنوعی لاما یا خبرهایی از انتشار نخسههای جدید آن را شنیدهاید. در اینجا ما هوش مصنوعی Llama را بررسی میکنیم و مدلهای آن را با هم مقایسه میکنیم.
وقتی که چت جیپیتی منتشر شد، بسیاری از شرکتهای بزرگ جهان متوجه شدند که اگر به سمت دنیای هوش مصنوعی حرکت نکنند، گوی رقابت را از دست خواهند داد. مایکروسافت که سهامدار Open AI بود، گوگل به سمت توسعه هوش مصنوعی Bard ( که حالا با نام Gemini شناخته میشود) رفت. ایلان ماسک در حال توسعه Grok است و …
در این میان شرکت متا، یعنی شرکت مادر فیسبوک و اینستاگرام نیز بیکار ننشست و از هوش مصنوعی Llama رونمایی کرد. هوش مصنوعی لاما خانوادهای از مدلهای زبانی بزرگ است که میتوانند زبان انسانی را درک کنند و سپس بر اساس ورودیای که دریافت کردهاند، متنی شبیه به انسان بنویسند.
انتشار اولین نسخه
اولین مجموعه از این مدل در ۲۴ فوریه ۲۰۲۳ (کمتر از یک سال و نیم پیش) منتشر شد. این مدل زبانی بزرگ به گونهای طراحی شده بود که کارآمد و موثر باشد و با اندازه های مختلف Llama-30B , Llama-13B, Llama-7B و Llama 65B رونمایی شد ( عددهایی که مشاهده میکنید تعداد پارامترها در این مدل ها است).
یکی از ویژگیهای مهم این مدل کارآمدی در مصرف منابع بود. یعنی بهگونهای طراحی شده بود که منابع محاسباتی و حافظه کمتری نیاز داشته باشد. این نسخه در ابتدا در اختیار محققان و دانشگان قرار گرفت تا از آن برای کارهای پژوهشی استفاده کنند. استفاده تجاری از این هوش مصنوعی نیازمند دریافت مجوزهای متا بود.
انتشار نسخه دوم لاما یا Llama 2 با مشارکت مایکروسافت
پنج ماه بعد، در ۱۸ جولای ۲۰۲۳، شرکت متا با همراهی مایکروسافت از دومین ورژن هوش مصنوعی لاما با نام Llama 2 رونمایی کرد. Llama 2 در اندازههای ۷ و ۱۳ و ۷۰ میلیارد پارامتری منتشر شد. معماری این نسخه چندان تفاوتی با نسل اول لاما نداشت اما دادههایی که برای آموزش آن به کار رفته بود ۴۰ درصد بزرگتر بود و همین موضوع کیفیت و عملکرد آن را افزایش میداد.
اتفاق مهم در نسخه Llama 2 این بود که این هوش مصنوعی به صورت باز هستند و همین موضوع سبب شد که شرکتها و پژوهشگران بتوانند از این مدل برای تحقیق و توسعه و اهداف تجاری به راحتی استفاده کنند. این هوش منصوعی حالا میتوانست در چتباتها و دستیارهای مجازی بکار گرفته شود.
Llama 3
در ۱۸ آوریل ۲۰۲۴، شرکت متا Llama 3 را منتشر کرد. لاما ۳ در دو وزن ۸ میلیارد پارامتری و ۷۰ میلیارد پارامتری منتشر شد. شرکت متا مدعی این موضوع بود که این هوش مصنوعی نسبت به بسیاری از رقبا از جمله Claude 3 عملکرد بهتری دارد.
لاما ۳ نسبت به نسخه ۲ کیفیت بسیار بالاتری داشت و در استدلال و برنامه نویسی عملکرد بهتری را از خود نشان داد. هوش مصنوعی Llama 3 محموعه دادههای آموزشی ای در حدود ۱۵ تریلیون توکن را استفاده کردند که تقریبا ۷ برابر بزرگتر از آنچیزی بود که در Llama 2 بکار گرفته شود بود. همچنین این نسخه با حجم قابل توجهی از دادههای غیر انگلیسی آموزش دیده بود که همین موضوع عملکرد آن در زبانهای غیر انگلیسی را بهبود بخشید.
Llama 3 از معماری ترانسفورماتور بهینه شده با ویژگی هایی مانند Grouped-Query Attention (GQA) برای بهبود مقیاس پذیری در طی استنتاج استفاده میکند. این مدل با تکنیکهای پیشرفتهای مانند تنظیم دقیق نظارت شده و یادگیری تقویتی با بازخورد انسانی برای افزایش مفید بودن و ایمنی آن آموزش دیده است.
Llama 3.1 منتشر شد.
در دوم مرداد ۱۴۰۳ ، شرکت متا از Llama 3.1 رونمایی کرد. این مدل در سه ورژن ۸ ، ۷۰ و ۴۰۵ میلیارد پارامتری به صورت اوپن سورس منتشر شد. در حالی که نسخه قبلی یعنی در نهایت ۷۰ میلیارد پارامتر داشت، ورژن ۴۰۵ میلیارد پارامتری هوش مصنوعی Llama 3.1 نشان از یک قدرت بسیار بالا دارد.
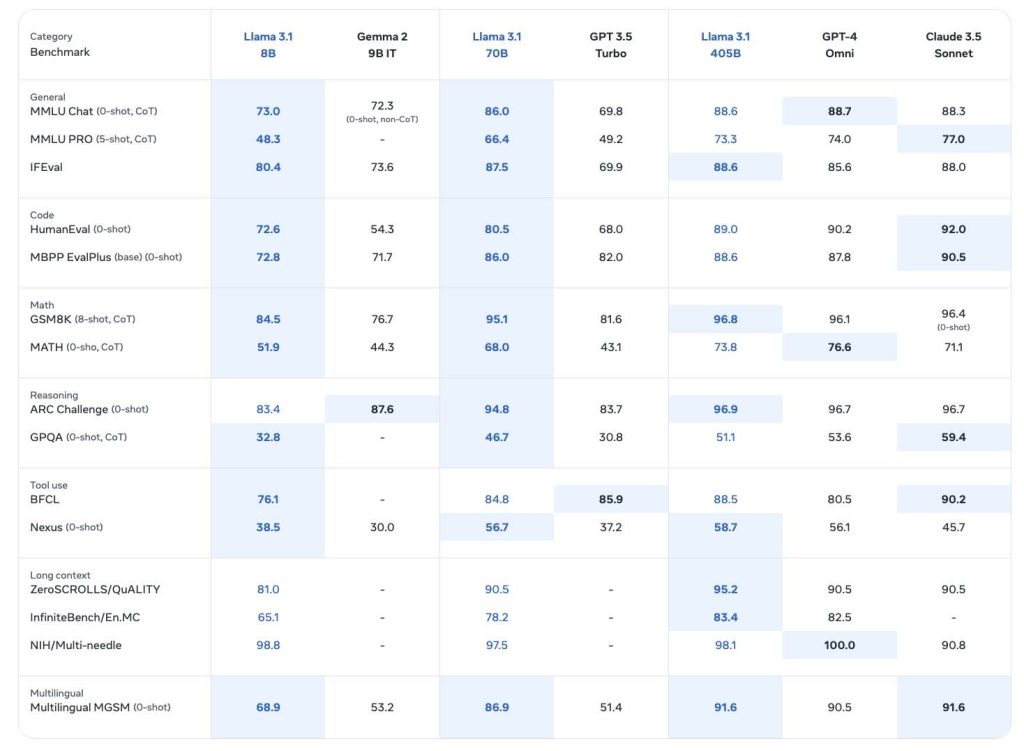
در بنچمارکی که شرکت متا منتشر کرده است. ورژن ۸ میلیاردی Llama 3.1 در بسیاری از زمینهها از نسخه ۹ میلیاردی هوش مصنوعی گاما ۲ بهتر عمل میکند. همچنین مقایسه ورژن ۷۰ میلیارد پارامتری با نسخه چت جیپیتی توربو ( برای آشنایی با چت جیپیتی و انواع نسخههای آن اینجا کلیک کنید) نشان میدهد که این هوش مصنوعی در بسیاری از حوزهها علی الخصوص عمومی و ریاضی و کد نویسی عملکردی بهتر از GPT 3.5 Turbo دارد.
مقایسه نسخه ۴۰۵ میلیاردی Llama 3.1 با GPT-4mini و Claude 3.5 sonnet هرچند در برخی از معیارها نتایج بهتر است اما برتری قابل توجهی را نشان نمیدهد و در برخی حوزهها ضعیف تر نیز هست.
